
搜索到
38
篇与
的结果
-
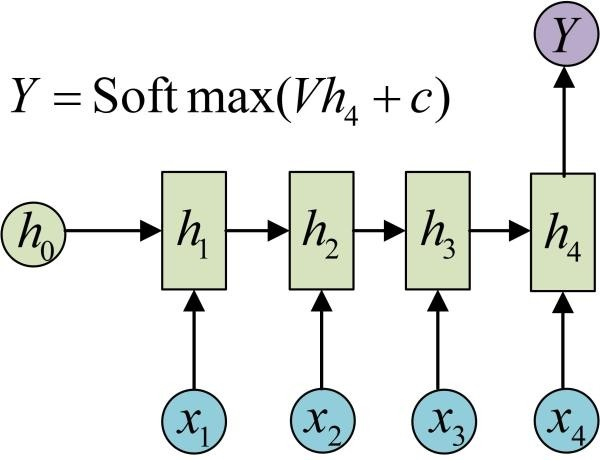
 循环神经网路 RNN 普通的RNN:小数据集 低算力S=f(winXt+b) St=f(WinXt+WSSt−1+b)变种输入序列,单输出单输入,输出序列输入不随序列变化原始的N to N的RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。下面介绍RNN最重要的一个变种:N to M。这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型。从名字就能看出,这个结构的原理是先编码后解码。左侧的RNN用来编码得到c,拿到c后再用右侧的RNN进行解码。得到c有多种方式:长短期记忆网络 LSTMforget gate 遗忘门f1=sigmoid(w1[St−1xt]+b1)input gate 输入门f2=sigmoid(w2[St−1xt]+b2)∗tanh(w2′[St−1xt]+b2′) ct=f1∗ct−1+f2
循环神经网路 RNN 普通的RNN:小数据集 低算力S=f(winXt+b) St=f(WinXt+WSSt−1+b)变种输入序列,单输出单输入,输出序列输入不随序列变化原始的N to N的RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。下面介绍RNN最重要的一个变种:N to M。这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型。从名字就能看出,这个结构的原理是先编码后解码。左侧的RNN用来编码得到c,拿到c后再用右侧的RNN进行解码。得到c有多种方式:长短期记忆网络 LSTMforget gate 遗忘门f1=sigmoid(w1[St−1xt]+b1)input gate 输入门f2=sigmoid(w2[St−1xt]+b2)∗tanh(w2′[St−1xt]+b2′) ct=f1∗ct−1+f2 -
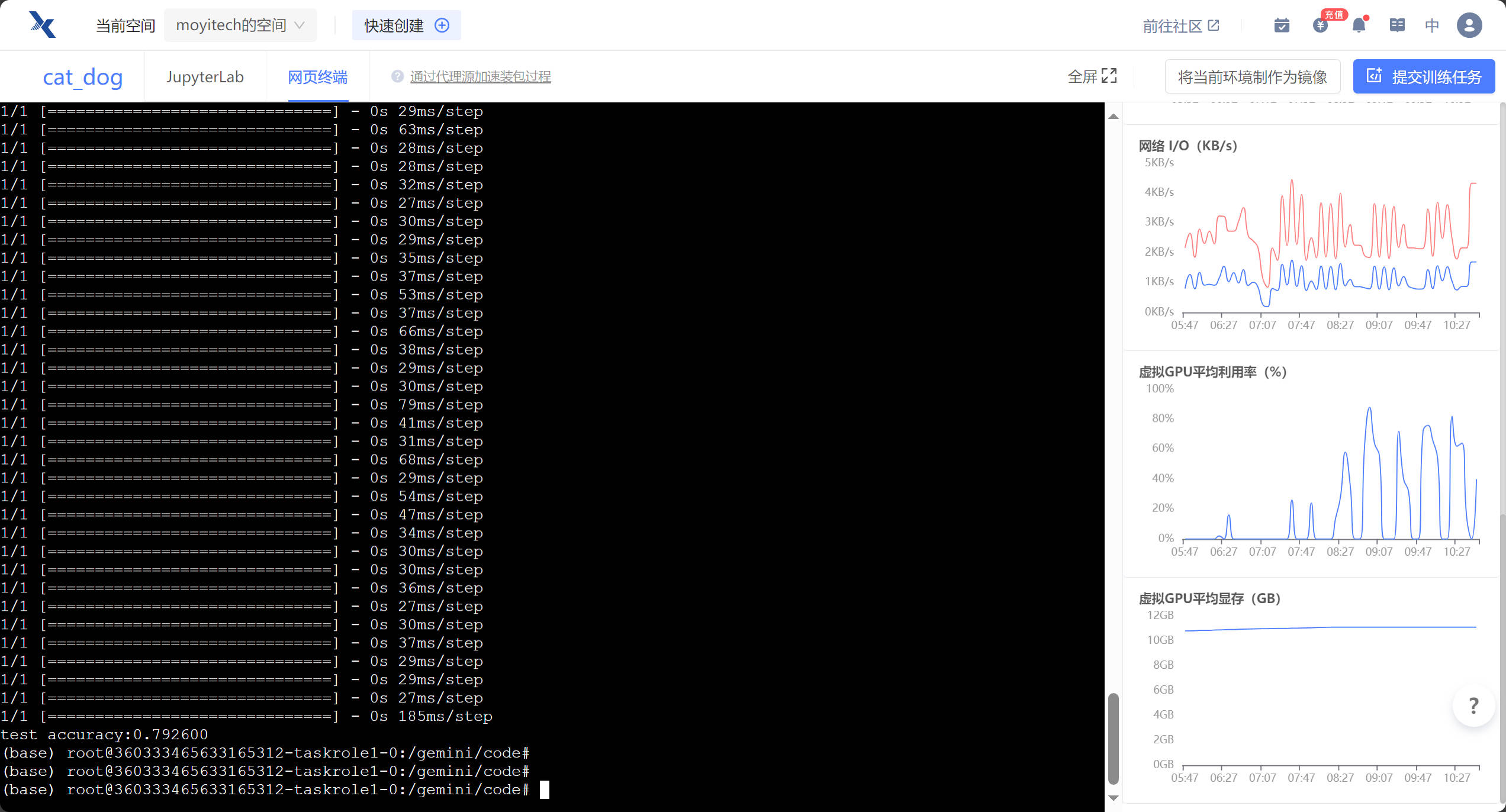
AI线上部署之猫狗识别 使用趋动云的在线Jupyter Notebook部署模型环境配置很简单,直接使用预置的镜像即可环境:Python 3TensorFlow 2代码 + 注释:import argparse import tensorflow as tf import os parser = argparse.ArgumentParser(description='Process some integers') # 使用argparse创建一个可以解析命令行参数的工具,description为描述信息 parser.add_argument('--mode', default='train', help='train or test') parser.add_argument("--num_epochs", default=5, type=int) # 设置epochs parser.add_argument("--batch_size", default=32, type=int) # 设置batch_seze parser.add_argument("--learning_rate", default=0.001) # 设置learning_rate parser.add_argument("--data_dir", default="/gemini/data-1") parser.add_argument("--train_dir", default="/gemini/output") args = parser.parse_args() # 将解析的结果存储在args中 # 图片的前置处理 def _decode_and_resize(filename, label): image_string = tf.io.read_file(filename) # 从文件中读取 image_decoded = tf.image.decode_jpeg(image_string, channels=3) # 解码jpeg为rgb三通道 image_resized = tf.image.resize(image_decoded, [150, 150]) / 255.0 # 将图片缩放、归一化 return image_resized, label if __name__ == "__main__": train_dir = args.data_dir + "/train" cats = [] dogs = [] for file in os.listdir(train_dir): # 遍历文件夹 if file.startswith("dog"): dogs.append(train_dir + "/" + file) else: cats.append(train_dir + "/" + file) print("dogSize:%d catSize:%d" % (len(cats), len(dogs))) train_cat_filenames = tf.constant(cats[:10000]) # 将文件名列表转化为张量 train_dog_filenames = tf.constant(dogs[:10000]) train_filenames = tf.concat([train_cat_filenames, train_dog_filenames], axis=-1) # axis=-1表示最后一个维度 train_labels = tf.concat([ tf.zeros(train_cat_filenames.shape, dtype=tf.int32), # 猫标为0 tf.ones(train_dog_filenames.shape, dtype=tf.int32) # 狗标为1 ], axis=-1) train_dataset = tf.data.Dataset.from_tensor_slices((train_filenames, train_labels)) # 创建一个dataset train_dataset = train_dataset.map( map_func=_decode_and_resize, num_parallel_calls=tf.data.experimental.AUTOTUNE # 指定为并行调用 ) train_dataset = train_dataset.shuffle(buffer_size=20000) # 打乱 train_dataset = train_dataset.batch(args.batch_size) # 设置batch_size train_dataset = train_dataset.prefetch(tf.data.experimental.AUTOTUNE) # 自动调整并行化程度,使训练时可异步预取数据,减少训练时间 model = tf.keras.Sequential([ # 定义模型网络 tf.keras.layers.Conv2D(32, 3, activation="relu", input_shape=(150, 150, 3)), tf.keras.layers.MaxPool2D(), tf.keras.layers.Conv2D(64, 3, activation="relu"), tf.keras.layers.MaxPool2D(), tf.keras.layers.Conv2D(128, 3, activation="relu"), tf.keras.layers.MaxPool2D(), tf.keras.layers.Conv2D(128, 3, activation="relu"), tf.keras.layers.MaxPool2D(), tf.keras.layers.Flatten(), tf.keras.layers.Dropout(0.5), tf.keras.layers.Dense(512, activation="relu"), tf.keras.layers.Dense(2, activation="softmax") ]) model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=args.learning_rate), # 定义优化器为Adam loss=tf.keras.losses.sparse_categorical_crossentropy, # 定义损失函数为交叉熵 metrics=[tf.keras.metrics.sparse_categorical_accuracy] # 定义模型评估指标为稀疏分类准确率 ) model.fit(train_dataset, epochs=args.num_epochs) # 开始训练 model.save(args.train_dir) # 保存模型 # 构建测试数据集 test_cat_filenames = tf.constant(cats[10000:]) test_dog_filenames = tf.constant(dogs[10000:]) test_filenames = tf.concat([test_cat_filenames, test_dog_filenames], axis=-1) test_labels = tf.concat([ tf.zeros(test_cat_filenames.shape, dtype=tf.int32), tf.ones(test_dog_filenames.shape, dtype=tf.int32) ], axis=-1) test_dataset = tf.data.Dataset.from_tensor_slices((test_filenames, test_labels)) test_dataset = test_dataset.map(_decode_and_resize) test_dataset = test_dataset.batch(args.batch_size) sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy() # 稀疏分类指标 for images, label in test_dataset: y_pred = model.predict(images) sparse_categorical_accuracy.update_state(y_true=label, y_pred=y_pred) # 更新准确率指标的状态 print("test accuracy:%f" % sparse_categorical_accuracy.result()) # 输出结果 训练命令:python $GEMINI_RUN/DogsVsCats.py --num_epochs 5 --data_dir $GEMINI_DATA_IN1/DogsVsCats/ --train_dir $GEMINI_DATA_OUT最终结果:学习心得:由于之前接触的都是pytorch,这次第一次接触了TensorFlow,学习到了很多TensorFlow的api和这次demo简洁优美的代码风格
-
Jupyter Notebook添加删除查看kernel 查看 Jupyter notebook kerneljupyter kernelspec list添加kernel# 首先进入道相应环境中 python -m pip install ipykernel python -m ipykernel install --user --name=kernelname --display-name showname # name为创建的文件夹名,showname为jupyter notebook展示的内核名删除jupyter kerneljupyter kernelspec remove kernelname
-
【Datawhale夏令营第三期】用户新增预测挑战赛 前言又又又参加了Datawhale的AI夏令营第二期的机器学习赛道~,没错这次还是机器学习(外加运营助教)baseline:https://aistudio.baidu.com/aistudio/projectdetail/6618108赛事任务基于提供的样本构建模型,预测用户的新增情况数据说明udmap: 以dict形式给出,需要自定义函数解析common_ts: 事件发生时间,可使用df.dt进行解析x1-x8: 某种特征,但不清楚含义,可通过后续画图分析进行处理target: 预测目标0或1二分类评估指标还是f1,F1 score解释: https://www.9998k.cn/archives/169.htmlF1 scoreF1 score = 2 * (precision * recall) / (precision + recall)precision and recall第一次看的时候还不太懂precision和recall的含义,也总结一下首先定义以下几个概念:TP(True Positive):真阳性TN (True Negative) : 真阴性FP(False Positive):假阳性FN(False Negative):假阴性precision = TP / (TP + FP)recall = TP / (TP + FN)accuracy = (TP + TN) / (TP + TN + FP + FN)分析baseline分析跑出来是0.62+使用了决策树模型进行训练对udmap特征进行了提取计算了eid的freq和mean通过df.dt提取了hour信息特征提取除去baseline的特征外,又借鉴了锂电池那次的baseline,提取了如下特征:dayofweekweekofyeardayofyearis_weekend调整后的分数为:0.75train_data['common_ts_hour'] = train_data['common_ts'].dt.hour test_data['common_ts_hour'] = test_data['common_ts'].dt.hour train_data['common_ts_minute'] = train_data['common_ts'].dt.minute + train_data['common_ts_hour'] * 60 test_data['common_ts_minute'] = test_data['common_ts'].dt.minute + test_data['common_ts_hour'] * 60 train_data['dayofweek'] = train_data['common_ts'].dt.dayofweek test_data['dayofweek'] = test_data['common_ts'].dt.dayofweek train_data["weekofyear"] = train_data["common_ts"].dt.isocalendar().week.astype(int) test_data["weekofyear"] = test_data["common_ts"].dt.isocalendar().week.astype(int) train_data["dayofyear"] = train_data["common_ts"].dt.dayofyear test_data["dayofyear"] = test_data["common_ts"].dt.dayofyear train_data["day"] = train_data["common_ts"].dt.day test_data["day"] = test_data["common_ts"].dt.day train_data['is_weekend'] = train_data['dayofweek'] // 6 test_data['is_weekend'] = test_data['dayofweek'] // 6x1-x8特征提取train_data['x1_freq'] = train_data['x1'].map(train_data['x1'].value_counts()) test_data['x1_freq'] = test_data['x1'].map(train_data['x1'].value_counts()) test_data['x1_freq'].fillna(test_data['x1_freq'].mode()[0], inplace=True) train_data['x1_mean'] = train_data['x1'].map(train_data.groupby('x1')['target'].mean()) test_data['x1_mean'] = test_data['x1'].map(train_data.groupby('x1')['target'].mean()) test_data['x1_mean'].fillna(test_data['x1_mean'].mode()[0], inplace=True) train_data['x2_freq'] = train_data['x2'].map(train_data['x2'].value_counts()) test_data['x2_freq'] = test_data['x2'].map(train_data['x2'].value_counts()) test_data['x2_freq'].fillna(test_data['x2_freq'].mode()[0], inplace=True) train_data['x2_mean'] = train_data['x2'].map(train_data.groupby('x2')['target'].mean()) test_data['x2_mean'] = test_data['x2'].map(train_data.groupby('x2')['target'].mean()) test_data['x2_mean'].fillna(test_data['x2_mean'].mode()[0], inplace=True) train_data['x3_freq'] = train_data['x3'].map(train_data['x3'].value_counts()) test_data['x3_freq'] = test_data['x3'].map(train_data['x3'].value_counts()) test_data['x3_freq'].fillna(test_data['x3_freq'].mode()[0], inplace=True) train_data['x4_freq'] = train_data['x4'].map(train_data['x4'].value_counts()) test_data['x4_freq'] = test_data['x4'].map(train_data['x4'].value_counts()) test_data['x4_freq'].fillna(test_data['x4_freq'].mode()[0], inplace=True) train_data['x6_freq'] = train_data['x6'].map(train_data['x6'].value_counts()) test_data['x6_freq'] = test_data['x6'].map(train_data['x6'].value_counts()) test_data['x6_freq'].fillna(test_data['x6_freq'].mode()[0], inplace=True) train_data['x6_mean'] = train_data['x6'].map(train_data.groupby('x6')['target'].mean()) test_data['x6_mean'] = test_data['x6'].map(train_data.groupby('x6')['target'].mean()) test_data['x6_mean'].fillna(test_data['x6_mean'].mode()[0], inplace=True) train_data['x7_freq'] = train_data['x7'].map(train_data['x7'].value_counts()) test_data['x7_freq'] = test_data['x7'].map(train_data['x7'].value_counts()) test_data['x7_freq'].fillna(test_data['x7_freq'].mode()[0], inplace=True) train_data['x7_mean'] = train_data['x7'].map(train_data.groupby('x7')['target'].mean()) test_data['x7_mean'] = test_data['x7'].map(train_data.groupby('x7')['target'].mean()) test_data['x7_mean'].fillna(test_data['x7_mean'].mode()[0], inplace=True) train_data['x8_freq'] = train_data['x8'].map(train_data['x8'].value_counts()) test_data['x8_freq'] = test_data['x8'].map(train_data['x8'].value_counts()) test_data['x8_freq'].fillna(test_data['x8_freq'].mode()[0], inplace=True) train_data['x8_mean'] = train_data['x8'].map(train_data.groupby('x8')['target'].mean()) test_data['x8_mean'] = test_data['x8'].map(train_data.groupby('x8')['target'].mean()) test_data['x8_mean'].fillna(test_data['x8_mean'].mode()[0], inplace=True)实测使用众数填充会比0填充好一点实测分数 0.76398无脑大招:AutoGluon直接上代码:import pandas as pd import numpy as np train_data = pd.read_csv('用户新增预测挑战赛公开数据/train.csv') test_data = pd.read_csv('用户新增预测挑战赛公开数据/test.csv') #autogluon from autogluon.tabular import TabularDataset, TabularPredictor clf = TabularPredictor(label='target') clf.fit( TabularDataset(train_data.drop(['uuid'], axis=1)), ) print("预测的正确率为:",clf.evaluate( TabularDataset(train_data.drop(['uuid'], axis=1)), ) ) pd.DataFrame({ 'uuid': test_data['uuid'], 'target': clf.predict(test_data.drop(['uuid'], axis=1)) }).to_csv('submit.csv', index=None)AutoGluon分数:0.79868使用x1-x8识别用户特征参考自Ivan大佬import pandas as pd import numpy as np train_data = pd.read_csv('用户新增预测挑战赛公开数据/train.csv') test_data = pd.read_csv('用户新增预测挑战赛公开数据/test.csv') user_df = train_data.groupby(by=['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8'])['target'].mean().reset_index( name='user_prob') from sklearn.tree import DecisionTreeClassifier for i in range(user_df.shape[0]): x1 = user_df.iloc[i, 0] x2 = user_df.iloc[i, 1] x3 = user_df.iloc[i, 2] x4 = user_df.iloc[i, 3] x5 = user_df.iloc[i, 4] x6 = user_df.iloc[i, 5] x7 = user_df.iloc[i, 6] x8 = user_df.iloc[i, 7] sub_train = train_data.loc[ (train_data['x1'] == x1) & (train_data['x2'] == x2) & (train_data['x3'] == x3) & (train_data['x4'] == x4) & (train_data['x5'] == x5) & (train_data['x6'] == x6) & (train_data['x7'] == x7) & (train_data['x8'] == x8) ] sub_test = test_data.loc[ (test_data['x1'] == x1) & (test_data['x2'] == x2) & (test_data['x3'] == x3) & (test_data['x4'] == x4) & (test_data['x5'] == x5) & (test_data['x6'] == x6) & (test_data['x7'] == x7) & (test_data['x8'] == x8) ] # print(sub_train.columns) clf = DecisionTreeClassifier() clf.fit( sub_train.loc[:, ['eid', 'common_ts']], sub_train['target'] ) try: test_data.loc[ (test_data['x1'] == x1) & (test_data['x2'] == x2) & (test_data['x3'] == x3) & (test_data['x4'] == x4) & (test_data['x5'] == x5) & (test_data['x6'] == x6) & (test_data['x7'] == x7) & (test_data['x8'] == x8), ['target'] ] = clf.predict( test_data.loc[ (test_data['x1'] == x1) & (test_data['x2'] == x2) & (test_data['x3'] == x3) & (test_data['x4'] == x4) & (test_data['x5'] == x5) & (test_data['x6'] == x6) & (test_data['x7'] == x7) & (test_data['x8'] == x8), ['eid', 'common_ts']] ) except: pass test_data.fillna(0, inplace=True) test_data['target'] = test_data.target.astype(int) test_data[['uuid','target']].to_csv('submit_2.csv', index=None)实测分数:0.831最后 修改代码,把fillna替换为如下代码from sklearn.tree import DecisionTreeClassifier clf = DecisionTreeClassifier() clf.fit( train_data.drop(['udmap', 'common_ts', 'uuid', 'target', 'common_ts_hour'], axis=1), train_data['target'] ) test_data.loc[pd.isna(test_data['target']),'target'] = \ clf.predict( test_data.loc[ pd.isna(test_data['target']), test_data.drop(['udmap', 'common_ts', 'uuid', 'target', 'common_ts_hour'], axis=1).columns] )最终分数: 0.8321
-
【Datawhale夏令营第二期】AI量化模型预测挑战赛 前言参加了Datawhale的AI夏令营第二期的机器学习赛道~,没错这次还是机器学习baseline:https://aistudio.baidu.com/aistudio/projectdetail/6598302?sUid=2554132&shared=1&ts=1690895519028赛事任务简单地说就是通过模型预测股票价格看这里: https://challenge.xfyun.cn/topic/info?type=quantitative-model数据说明date:日期time:时间戳close:最新价/收盘价amount_delta:成交量变化 从上个tick到当前tick发生的成交金额n_midprice:中间价 标准化后的中间价,以涨跌幅表示n_bidN: 买N价n_bsizeN:买N量n_ask:卖N价n_asize1:卖N量labelN:Ntick价格移动方向 Ntick之后中间价相对于当前tick的移动方向,0为下跌,1为不变,2为上涨评估指标采用macro-F1 score进行评价,取label_5, label_10, label_20, label_40, label_60五项中的最高分作为最终得分。F1 score解释: https://www.9998k.cn/archives/169.htmlF1 scoreF1 score = 2 * (precision * recall) / (precision + recall)precision and recall第一次看的时候还不太懂precision和recall的含义,也总结一下首先定义以下几个概念:TP(True Positive):将本类归为本类TN (True Negative) : 将其他类归为其他类FP(False Positive):错将其他类预测为本类FN(False Negative):本类标签预测为其他类标precision = TP / (TP + FP)recall = TP / (TP + FN)accuracy = (TP + TN) / (TP + TN + FP + FN)分析baseline分析本次baseline使用了catboost,相比于上次的LightGBM,可以方便地调用显卡进行训练: 【Datawhale夏令营第二期】CatBoost如何使用GPU在本次的baseline中,只需在cv_model函数中的line15中的params: dict中添加一个键即可:'task_type' : 'GPU'代码解析path = 'AI量化模型预测挑战赛公开数据/' # 数据目录 train_files = os.listdir(path+'train') # 获取目录下的文件 train_df = pd.DataFrame() # 定义一个空的DataFrame for filename in tqdm.tqdm(train_files): # 遍历文件并使用tqdm显示 if os.path.isdir(path+'train/'+filename): # 先判断是否是缓存文件夹直接跳过,防止bug continue tmp = pd.read_csv(path+'train/'+filename) # 使用tmp变量存储读取转换后的DataFrame tmp['file'] = filename # 记录文件名 train_df = pd.concat([train_df, tmp], axis=0, ignore_index=True) # 合并tmp数据到之前的df test_files = os.listdir(path+'test') test_df = pd.DataFrame() for filename in tqdm.tqdm(test_files): if os.path.isdir(path+'train/'+filename): continue tmp = pd.read_csv(path+'test/'+filename) tmp['file'] = filename test_df = pd.concat([test_df, tmp], axis=0, ignore_index=True)特征工程1.0wap(Weighted Average Price)加权平均价格 = (买价 买量 + 卖价 买量) / (买量 + 卖量)# 计算wap数值 train_df['wap1'] = (train_df['n_bid1']*train_df['n_bsize1'] + train_df['n_ask1']*train_df['n_asize1'])/(train_df['n_bsize1'] + train_df['n_asize1']) test_df['wap1'] = (test_df['n_bid1']*test_df['n_bsize1'] + test_df['n_ask1']*test_df['n_asize1'])/(test_df['n_bsize1'] + test_df['n_asize1']) train_df['wap2'] = (train_df['n_bid2']*train_df['n_bsize2'] + train_df['n_ask2']*train_df['n_asize2'])/(train_df['n_bsize2'] + train_df['n_asize2']) test_df['wap2'] = (test_df['n_bid2']*test_df['n_bsize2'] + test_df['n_ask2']*test_df['n_asize2'])/(test_df['n_bsize2'] + test_df['n_asize2']) train_df['wap3'] = (train_df['n_bid3']*train_df['n_bsize3'] + train_df['n_ask3']*train_df['n_asize3'])/(train_df['n_bsize3'] + train_df['n_asize3']) test_df['wap3'] = (test_df['n_bid3']*test_df['n_bsize3'] + test_df['n_ask3']*test_df['n_asize3'])/(test_df['n_bsize3'] + test_df['n_asize3'])wap1wap2wap3特征工程2.0 # 为了保证时间顺序的一致性,故进行排序 train_df = train_df.sort_values(['file','time']) test_df = test_df.sort_values(['file','time']) # 当前时间特征 # 围绕买卖价格和买卖量进行构建 # 暂时只构建买一卖一和买二卖二相关特征,进行优化时可以加上其余买卖信息 train_df['wap1'] = (train_df['n_bid1']*train_df['n_bsize1'] + train_df['n_ask1']*train_df['n_asize1'])/(train_df['n_bsize1'] + train_df['n_asize1']) test_df['wap1'] = (test_df['n_bid1']*test_df['n_bsize1'] + test_df['n_ask1']*test_df['n_asize1'])/(test_df['n_bsize1'] + test_df['n_asize1']) train_df['wap2'] = (train_df['n_bid2']*train_df['n_bsize2'] + train_df['n_ask2']*train_df['n_asize2'])/(train_df['n_bsize2'] + train_df['n_asize2']) test_df['wap2'] = (test_df['n_bid2']*test_df['n_bsize2'] + test_df['n_ask2']*test_df['n_asize2'])/(test_df['n_bsize2'] + test_df['n_asize2']) train_df['wap_balance'] = abs(train_df['wap1'] - train_df['wap2']) train_df['price_spread'] = (train_df['n_ask1'] - train_df['n_bid1']) / ((train_df['n_ask1'] + train_df['n_bid1'])/2) train_df['bid_spread'] = train_df['n_bid1'] - train_df['n_bid2'] train_df['ask_spread'] = train_df['n_ask1'] - train_df['n_ask2'] train_df['total_volume'] = (train_df['n_asize1'] + train_df['n_asize2']) + (train_df['n_bsize1'] + train_df['n_bsize2']) train_df['volume_imbalance'] = abs((train_df['n_asize1'] + train_df['n_asize2']) - (train_df['n_bsize1'] + train_df['n_bsize2'])) test_df['wap_balance'] = abs(test_df['wap1'] - test_df['wap2']) test_df['price_spread'] = (test_df['n_ask1'] - test_df['n_bid1']) / ((test_df['n_ask1'] + test_df['n_bid1'])/2) test_df['bid_spread'] = test_df['n_bid1'] - test_df['n_bid2'] test_df['ask_spread'] = test_df['n_ask1'] - test_df['n_ask2'] test_df['total_volume'] = (test_df['n_asize1'] + test_df['n_asize2']) + (test_df['n_bsize1'] + test_df['n_bsize2']) test_df['volume_imbalance'] = abs((test_df['n_asize1'] + test_df['n_asize2']) - (test_df['n_bsize1'] + test_df['n_bsize2'])) # 历史平移 # 获取历史信息 for val in ['wap1','wap2','wap_balance','price_spread','bid_spread','ask_spread','total_volume','volume_imbalance']: for loc in [1,5,10,20,40,60]: train_df[f'file_{val}_shift{loc}'] = train_df.groupby(['file'])[val].shift(loc) test_df[f'file_{val}_shift{loc}'] = test_df.groupby(['file'])[val].shift(loc) # 差分特征 # 获取与历史数据的增长关系 for val in ['wap1','wap2','wap_balance','price_spread','bid_spread','ask_spread','total_volume','volume_imbalance']: for loc in [1,5,10,20,40,60]: train_df[f'file_{val}_diff{loc}'] = train_df.groupby(['file'])[val].diff(loc) test_df[f'file_{val}_diff{loc}'] = test_df.groupby(['file'])[val].diff(loc) # 窗口统计 # 获取历史信息分布变化信息 # 可以尝试更多窗口大小已经统计方式,如min、max、median等 for val in ['wap1','wap2','wap_balance','price_spread','bid_spread','ask_spread','total_volume','volume_imbalance']: train_df[f'file_{val}_win7_mean'] = train_df.groupby(['file'])[val].transform(lambda x: x.rolling(window=7, min_periods=3).mean()) train_df[f'file_{val}_win7_std'] = train_df.groupby(['file'])[val].transform(lambda x: x.rolling(window=7, min_periods=3).std()) test_df[f'file_{val}_win7_mean'] = test_df.groupby(['file'])[val].transform(lambda x: x.rolling(window=7, min_periods=3).mean()) test_df[f'file_{val}_win7_std'] = test_df.groupby(['file'])[val].transform(lambda x: x.rolling(window=7, min_periods=3).std()) # 时间相关特征 train_df['hour'] = train_df['time'].apply(lambda x:int(x.split(':')[0])) test_df['hour'] = test_df['time'].apply(lambda x:int(x.split(':')[0])) train_df['minute'] = train_df['time'].apply(lambda x:int(x.split(':')[1])) test_df['minute'] = test_df['time'].apply(lambda x:int(x.split(':')[1])) # 入模特征 cols = [f for f in test_df.columns if f not in ['uuid','time','file']]模型训练def cv_model(clf, train_x, train_y, test_x, clf_name, seed = 2023): folds = 5 kf = KFold(n_splits=folds, shuffle=True, random_state=seed) oof = np.zeros([train_x.shape[0], 3]) test_predict = np.zeros([test_x.shape[0], 3]) cv_scores = [] for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)): print('************************************ {} ************************************'.format(str(i+1))) trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index] if clf_name == "cat": params = {'learning_rate': 0.12, 'depth': 9, 'bootstrap_type':'Bernoulli','random_seed':2023, 'od_type': 'Iter', 'od_wait': 100, 'random_seed': 11, 'allow_writing_files': False, 'loss_function': 'MultiClass', 'task_type' : 'GPU'} # 使用'task_type' : 'GPU'可利用gpu加速训练 model = clf(iterations=2000, **params) model.fit(trn_x, trn_y, eval_set=(val_x, val_y), metric_period=200, use_best_model=True, cat_features=[], verbose=1) val_pred = model.predict_proba(val_x) test_pred = model.predict_proba(test_x) oof[valid_index] = val_pred test_predict += test_pred / kf.n_splits F1_score = f1_score(val_y, np.argmax(val_pred, axis=1), average='macro') cv_scores.append(F1_score) print(cv_scores) return oof, test_predict for label in ['label_5','label_10','label_20','label_40','label_60']: print(f'=================== {label} ===================') cat_oof, cat_test = cv_model(CatBoostClassifier, train_df[cols], train_df[label], test_df[cols], 'cat') train_df[label] = np.argmax(cat_oof, axis=1) test_df[label] = np.argmax(cat_test, axis=1)疑问为什么没有使用rnn或lstm进行预测?代码