
搜索到
8
篇与
的结果
-
 AAR论文阅读 论文简介标题:Augmentation-Adapted Retriever Improves Generalization of Language Models as Generic Plug-In摘要:Retrieval augmentation can aid language models (LMs) in knowledge-intensive tasks by supplying them with external information. Prior works on retrieval augmentation usually jointly fine-tune the retriever and the LM, making them closely coupled. In this paper, we explore the scheme of generic retrieval plug-in: the retriever is to assist target LMs that may not be known beforehand or are unable to be fine-tuned together. To retrieve useful documents for unseen target LMs, we propose augmentation-adapted retriever (AAR), which learns LM’s preferences obtained from a known source LM. Experiments on the MMLU and PopQA datasets demonstrate that our AAR trained with a small source LM is able to significantly improve the zero-shot generalization of larger target LMs ranging from 250M Flan-T5 to 175B InstructGPT. Further analysis indicates that the preferences of different LMs overlap, enabling AAR trained with a single source LM to serve as a generic plug-in for various target LMs. Our code is open-sourced at https://github.com/OpenMatch/AugmentationAdapted-Retriever.一种名为“Augmentation-Adapted Retriever(AAR)”的方法,用于改进语言模型在无监督任务中的泛化能力。AAR 旨在为无法联合微调的黑盒大模型(如GPT)提供外部信息支持,并增强其在知识密集型任务中的表现。与现有的检索增强方法不同,AAR 通过从一个较小的已知模型(source LM)学习目标模型的偏好,从而适应不同的大模型。文章通过在 MMLU 和 PopQA 数据集上的实验表明,AAR 能显著提升目标大模型的零样本泛化能力,并且能够作为一个通用插件为各种目标模型服务。论文解读在现在的RAG任务中,包含了Retriever和LLM两个部分,通常情况下二者是分别进行预训练的,Retriever负责从嵌入的向量数据库中检索最相关的文档或片段,LLM负责生成。RAG和fine-tuning并不冲突,通过fine-tuning可以让Retriever和LLM紧密耦合,提升RAG系统的性能。这种方法适用于白盒子模型,但是对于提供线上API的黑盒子模型,我们多数情况下无法进行fine-tuning,所以本文提出了AAR方法,可以在Retriever更符合LLM的需要,从而无需对黑盒子模型进行fine-tuning。我们现在的Retriever一般使用的text embedding模型是通过对比学习进行训练。数据集的是使用人工标注的Positive Doc和自动筛选出来的Negative Doc(如ANCE)进行训练,由此得到的Retriever是满足了人工筛选的偏好,而不是LLM的偏好。由于LLM的训练数据有很大的overlap,所以我们可以使用一个很小的source LM(如Flan-T5)的偏好来替代LLM的偏好,那么Positive Docs就是人工标注doc和通过source LM计算出偏好更高的doc的并集,Negtive Docs就是沿用了ANCE的结果。对于这篇文章,我的理解是。其实作者借鉴了ANCE的思想做了一个Positive Doc的训练增强,从而提升了text embedding模型的检索能力,使其能够检索到更多source LM(或LLM)喜欢的docs。
AAR论文阅读 论文简介标题:Augmentation-Adapted Retriever Improves Generalization of Language Models as Generic Plug-In摘要:Retrieval augmentation can aid language models (LMs) in knowledge-intensive tasks by supplying them with external information. Prior works on retrieval augmentation usually jointly fine-tune the retriever and the LM, making them closely coupled. In this paper, we explore the scheme of generic retrieval plug-in: the retriever is to assist target LMs that may not be known beforehand or are unable to be fine-tuned together. To retrieve useful documents for unseen target LMs, we propose augmentation-adapted retriever (AAR), which learns LM’s preferences obtained from a known source LM. Experiments on the MMLU and PopQA datasets demonstrate that our AAR trained with a small source LM is able to significantly improve the zero-shot generalization of larger target LMs ranging from 250M Flan-T5 to 175B InstructGPT. Further analysis indicates that the preferences of different LMs overlap, enabling AAR trained with a single source LM to serve as a generic plug-in for various target LMs. Our code is open-sourced at https://github.com/OpenMatch/AugmentationAdapted-Retriever.一种名为“Augmentation-Adapted Retriever(AAR)”的方法,用于改进语言模型在无监督任务中的泛化能力。AAR 旨在为无法联合微调的黑盒大模型(如GPT)提供外部信息支持,并增强其在知识密集型任务中的表现。与现有的检索增强方法不同,AAR 通过从一个较小的已知模型(source LM)学习目标模型的偏好,从而适应不同的大模型。文章通过在 MMLU 和 PopQA 数据集上的实验表明,AAR 能显著提升目标大模型的零样本泛化能力,并且能够作为一个通用插件为各种目标模型服务。论文解读在现在的RAG任务中,包含了Retriever和LLM两个部分,通常情况下二者是分别进行预训练的,Retriever负责从嵌入的向量数据库中检索最相关的文档或片段,LLM负责生成。RAG和fine-tuning并不冲突,通过fine-tuning可以让Retriever和LLM紧密耦合,提升RAG系统的性能。这种方法适用于白盒子模型,但是对于提供线上API的黑盒子模型,我们多数情况下无法进行fine-tuning,所以本文提出了AAR方法,可以在Retriever更符合LLM的需要,从而无需对黑盒子模型进行fine-tuning。我们现在的Retriever一般使用的text embedding模型是通过对比学习进行训练。数据集的是使用人工标注的Positive Doc和自动筛选出来的Negative Doc(如ANCE)进行训练,由此得到的Retriever是满足了人工筛选的偏好,而不是LLM的偏好。由于LLM的训练数据有很大的overlap,所以我们可以使用一个很小的source LM(如Flan-T5)的偏好来替代LLM的偏好,那么Positive Docs就是人工标注doc和通过source LM计算出偏好更高的doc的并集,Negtive Docs就是沿用了ANCE的结果。对于这篇文章,我的理解是。其实作者借鉴了ANCE的思想做了一个Positive Doc的训练增强,从而提升了text embedding模型的检索能力,使其能够检索到更多source LM(或LLM)喜欢的docs。 -
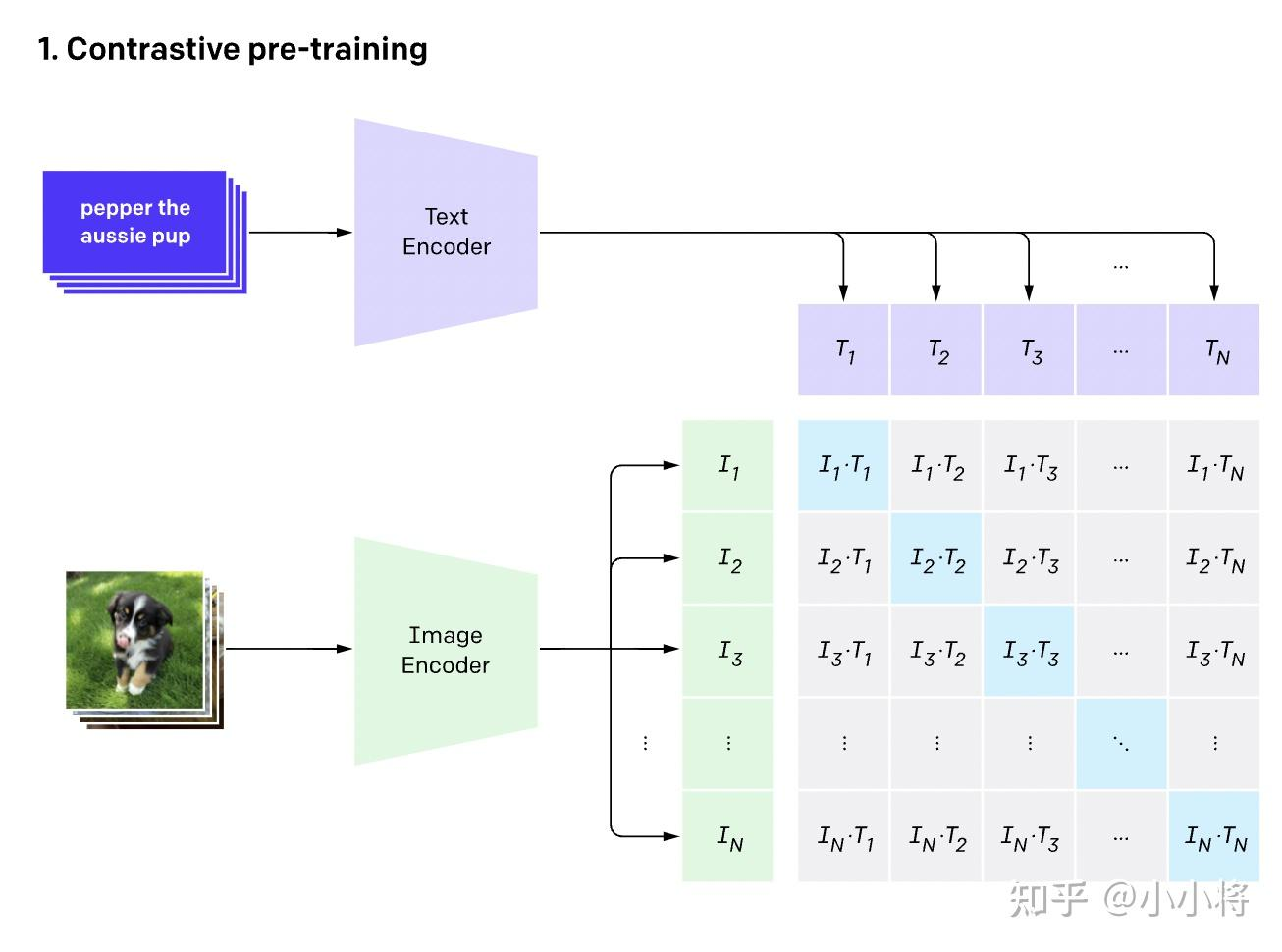
多模态初探——驾驶汽车虚拟仿真视频数据理解 近期Datawhale组织了《2023全球智能汽车AI挑战赛——赛道二:智能驾驶汽车虚拟仿真视频数据理解赛道》比赛的赛事实践活动赛题:智能驾驶汽车虚拟仿真视频数据理解赛道任务:输入:元宇宙仿真平台生成的前视摄像头虚拟视频数据(8-10秒左右);输出:对视频中的信息进行综合理解,以指定的json文件格式,按照数据说明中的关键词(key)填充描述型的文本信息(value,中文/英文均可以);baseline理解CLIPbaseline主要采用了CLIP模型:CLIP是用文本作为监督信号来训练可迁移的视觉模型,特此学习一下CLIPCLIP参考资料:https://zhuanlan.zhihu.com/p/493489688How CLIP WorksCLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,CLIP的训练数据是文本-图像对:(Text, Img)一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。如下图所示,CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。Text Encoder:text transformerImage Encoder: CNN or vision transformer这里对提取的文本特征和图像特征进行对比学习。对于一个包含N个文本-图像对的训练batch,将N个文本特征和N个图像特征两两组合,CLIP模型会预测出N²个可能的文本-图像对的相似度,这里的相似度直接计算文本特征和图像特征的余弦相似性(cosine similarity),即上图所示的矩阵。这里共有N个正样本,即真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的N²−N个文本-图像对为负样本,那么CLIP的训练目标就是最大N个正样本的相似度,同时最小化N²−N个负样本的相似度How to zero-shot by CLIP与YOLO中使用的先预训练然后微调不同,CLIP可以直接实现zero-shot的图像分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类根据任务的分类标签构建每个类别的描述文本:A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为N,那么将得到N个文本特征;将要预测的图像送入Image Encoder得到图像特征,然后与N个文本特征计算缩放的余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果,进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率在飞桨平台使用CLIP# 由于在平台没有默认安装CLIP模块,故需要先执行安装命令 !pip install paddleclip# 安装完后直接通过clip导入 from clip import tokenize, load_model # 载入预训练模型 model, transforms = load_model('ViT_B_32', pretrained=True)Pillow和OpenCV由于在之前仅仅接触过几次cv2和pil,都是直接从网上搜完代码直接调用的,没有深入里结果里面的具体含义,这次借着本次组队学习的机会,系统梳理一下cv2和pil的API先来看下本次baseline所用到的APIPIL# 导入pillow库中的Image from PIL import Image # 读入文件后是PIL类型(RGB) img = Image.open("zwk.png") # 补充:pytorch的顺序是(batch,c,h,w),tensorflow、numpy中是(batch,h,w,c)cv2# 导入cv2 import cv2 # 连接摄像头或读取视频文件,传入数字n代表第n号摄像头(从0开始),传入路径读取视频文件 cap = cv2.VideoCapture() # 按帧读取视频,ret为bool,frame为帧 ret, frame = cap.read() # 获取总帧数 cap.get(cv2.CAP_PROP_FRAME_COUNT) # 如果要抄中间的帧,需要先跳转到指定位置 cap.set(cv2.CAP_PROP_POS_FRAMES, n) # 由于cv2读取的图片默认BGR,而模型需要传入标准的RGB形式图片 image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 色彩通道转换:BGR -> RGB改进将需要预测的keywords改为["weather", "road_structure", "period", 'scerario'],可以使分数从93提升到119,看来CLIP对于识别一些诸如天气环境等静态信息还是比较有优势的。修改抽帧位置,但没有改进,可以再次尝试抽取多帧进行投票。(其实还试过切换为GPU,把整个视频所有帧都抽出来组成一个batch放进去计算整体概率,但是效果也不好)frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 获取视频总帧数 middle_frame_index = frame_count // 2 cap.set(cv2.CAP_PROP_POS_FRAMES, middle_frame_index) # 设置跳转当前位置到中间帧
-
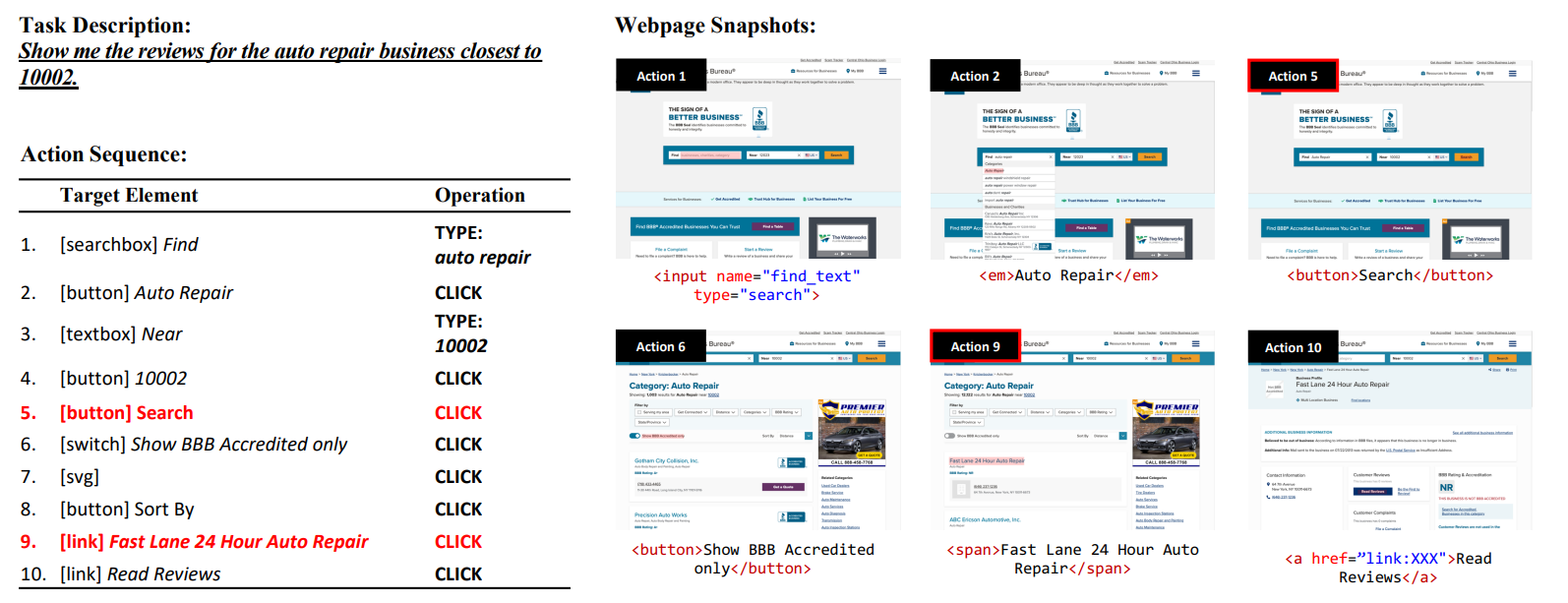
Mind2Web: Towards a Generalist Agent for the Web 论文解读 主页:https://osu-nlp-group.github.io/Mind2Web训练集:https://huggingface.co/datasets/osunlp/Mind2Web概要本文介绍了一个名为MIND2WEB的数据集,用于开发和评估Web通用代理,可以使用自然语言输入指令,使之可以在任何复杂的网站上执行操作。对比前人缺陷:现有的用于Web代理的数据集要么使用模拟网站,要么仅涵盖有限的网站和任务集,因此不适用于通用的Web代理。本文优势:MIND2WEB数据集包含来自137个网站、跨足31个领域的超过2,000个开放式任务,以及为这些任务收集的众包行动序列。MIND2WEB为构建通用Web代理提供了三个必要的要素:多样化的领域、网站和任务使用真实世界的网站而不是模拟和简化的网站广泛的用户交互模式。基于MIND2WEB,作者进行了首次尝试使用大型语言模型(LLMs)构建通用Web代理。由于真实世界网站的原始HTML通常元素过多无法直接输入LLM,本文的方案为:先通过小型LM进行筛选,再输入到LLM中,可以显著提升模型的效果和效率。MIND2WEB 数据集介绍来自于真实网站的捕捉涵盖领域广网站的快照和交互捕获完全任务定义该数据集旨在使代理通过一系列操作完成特定任务任务描述:是高级的,而不是避免了低级的、一步一步的指令。操作序列:(目标元素,操作)->(目标元素,操作)-> ... ->(目标元素,操作)三种常见操作:点击(包括悬停和按回车)、输入、选择操作序列通常跨越一个站点的多个网页。网页快照:HTML、DOM、HAR等过程信息执行方式:逐步预测、执行,input:当前网页、历史操作,output:接下来的操作 (有RNN的意思)数据收集数据通过亚马逊众包平台(Amazon Mechanical Turk)收集,主要分为三个阶段:第一阶段-任务提出:首先要求工作者提出可以在给定网站上执行的任务。作者会仔细审核提出的任务,并选择在第二阶段进行注释的可行且有趣的任务。第二阶段-任务演示:要求工作者演示如何在网站上执行任务。使用 Playwright 开发了一个注释工具,记录交互跟踪并在每个步骤中对网页进行快照。如图 2 所示,用红色标记的操作将导致转换到新网页。第三阶段-任务验证:作者验证所有任务,以确保所有操作都是正确的,任务描述正确地反映了注释的操作。与前人的比较 及 研究挑战采用真实的网页,更符合实际网页元素多、复杂度高,未进行人工简化任务等级高,更接近日常使用先前的研究通常提供逐步的指令,并主要关注测试代理将低级指令转化为操作的能力,例如,“在位置字段中输入纽约,单击搜索按钮并选择明天标签”本文数据集只提供高级目标,例如,“纽约明天的天气如何?”故这种数据集(Mind2Web)对于代理模型的训练及应用来说提出了很大的挑战。MindAct 框架为了使用Mind2Web数据集,引入了MindAct框架由于原始HTML过大,直接输入到LLM中消耗资源过大,MindAct将此分为二阶段过程(如图三)第一阶段:如图四,使用一个Small LM,从HTML中元素中筛选出几个候选元素第二阶段:将候选元素合并成HTML片段传入到LLM进行最后预测(元素 + 操作)Small LM 用于筛选;LLM用于预测通过Small LM生成小模型feature: Task Description + Previous Actionstarget: Top-k Elements通过LLM预测操作LLM用于判别 比 生成更有效率故LM被训练为从一系列选项中进行选择,而不是生成完整的目标元素Divide the top-k candidates into multiple clusters of five options. If more than one option is selected after a round,Form new groups with the selected ones. This process repeats until a single element is selected, or alloptions are rejected by the modeltest result:为什么MindAct和两个baseline不使用相同的LLM以控制变量?baseline1: Classfication,仅使用Debertab进行 元素 预测baseline2: Generation,使用Flan-T5直接进行 元素+操作 的预测实验实验步骤Test-Cross-Domain:使用不同的域名进行预测Test-Cross-Website:使用同域的网站预测TestCross-Task:使用相同的网站预测数据预处理和评估分别使用Element Accuracy、Operation F1、Step Success Rate、Success Rate对数据进行评估实验结果第一步候选生成使用了微调的DeBERTa 作为Small LM,用于第一步的候选生成(For efficiency, use the base version DeBERTaB with 86M parameters.)分别获得了88.9% / 85.3% / 85.7% 的recall取k=50,即top-50用于下一步预测。第二步操作预测使用Flan-T5作为生成模型尽管是大模型(220M for Flan-T5),但在元素选择方面表现先不佳使用上述MindAct中使用的multi-choice QA formulation方法很有效The best model achieves 52.0% step success rate under Cross-Task setting, and 38.9% / 39.6% when generalizing to unseen websites(Cross-Website) and domains(Cross-Domain).However, the overall task success rate remains low for all models, as the agent often commits at least one error step in most cases.Three Levels of Generalization模型均在Cross-Task表现最佳、但在Cross-Website、Cross-Domain中低于Cross-Task 10%以上。由此可见,对于未见过的环境进行预测是目前最大的问题。在图6中可见,Cross-Website、Cross-Domain中的表现很相近。就此可推断,首要问题在于网站的设计和交互逻辑、而不是域名特性。对于网站之间的一些共同的操作,预训练语言模型已经有了可以解析复杂任务的能力。在具体环境中,将这些知识转化为可操作的步骤仍然是一个相当大的挑战。In-context Learning with LLM分别使用MINDACT的方法在GPT-3.5和GPT-4进行了测试,结果如下:GPT-3.5表现不好,在元素选择正确率上仅有20%GPT-4要稍好一些,与微调过的Flan-T5不相上下,表明用大语言模型在此有很大的潜力但GPT-4运行成本很高,使用较小规模的模型是一个很好的发展方向
-
AI线上部署之ChatGLM 使用趋动云的在线Jupyter Notebook部署模型环境配置很简单,直接使用预置的镜像即可环境:Python 3PyTorch代码 + 注释:# cli_demo.py import os import platform import signal from transformers import AutoTokenizer, AutoModel import readline # 从指定路径加载预训练的tokenizer和model,允许信任远程代码 tokenizer = AutoTokenizer.from_pretrained("/gemini/data-2", trust_remote_code=True) model = AutoModel.from_pretrained("/gemini/data-2", trust_remote_code=True).cuda() # 若要支持多显卡,请使用下面两行代码替换上面一行,并根据实际显卡数量设置num_gpus # from utils import load_model_on_gpus # model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2) model = model.eval() # 获取操作系统信息,以便在不同操作系统上清屏 os_name = platform.system() clear_command = 'cls' if os_name == 'Windows' else 'clear' stop_stream = False # 构建用户提示信息,包括对话历史、清空历史和终止程序的说明 def build_prompt(history): prompt = "欢迎使用 ChatGLM2-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序" for query, response in history: prompt += f"\n\n用户:{query}" prompt += f"\n\nChatGLM2-6B:{response}" return prompt # 处理终止信号的函数 def signal_handler(signal, frame): global stop_stream stop_stream = True # 主函数 def main(): past_key_values, history = None, [] global stop_stream print("欢迎使用 ChatGLM2-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序") while True: query = input("\n用户:") if query.strip() == "stop": # 如果用户输入"stop",退出程序 break if query.strip() == "clear": # 如果用户输入"clear",清空对话历史并清屏 past_key_values, history = None, [] os.system(clear_command) print("欢迎使用 ChatGLM2-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序") continue print("\nChatGLM:", end="") current_length = 0 # 使用模型进行对话生成 for response, history, past_key_values in model.stream_chat(tokenizer, query, history=history, past_key_values=past_key_values, return_past_key_values=True): if stop_stream: # 如果接收到终止信号,停止对话生成 stop_stream = False break else: print(response[current_length:], end="", flush=True) current_length = len(response) print("") if __name__ == "__main__": main() 命令行模式命令:python ChatGLM2-6B/cli_demo.py最终结果:web模式:需要安装streamlitpip install streamlit然后在命令行使用streamlit运行web_demo2.pystreamlit run web_demo2.py --server.port=77使用streamlit可以很方便地实现web界面,无需html、css、js的知识都可以用 https://zhuanlan.zhihu.com/p/448853407
-
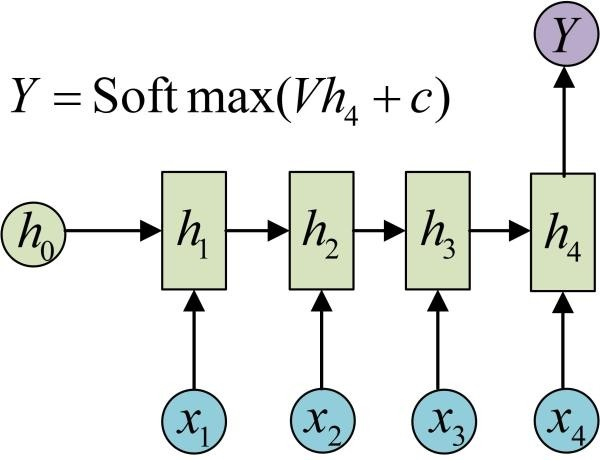
循环神经网路 RNN 普通的RNN:小数据集 低算力S=f(winXt+b) St=f(WinXt+WSSt−1+b)变种输入序列,单输出单输入,输出序列输入不随序列变化原始的N to N的RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。下面介绍RNN最重要的一个变种:N to M。这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型。从名字就能看出,这个结构的原理是先编码后解码。左侧的RNN用来编码得到c,拿到c后再用右侧的RNN进行解码。得到c有多种方式:长短期记忆网络 LSTMforget gate 遗忘门f1=sigmoid(w1[St−1xt]+b1)input gate 输入门f2=sigmoid(w2[St−1xt]+b2)∗tanh(w2′[St−1xt]+b2′) ct=f1∗ct−1+f2