
搜索到
12
篇与
的结果
-
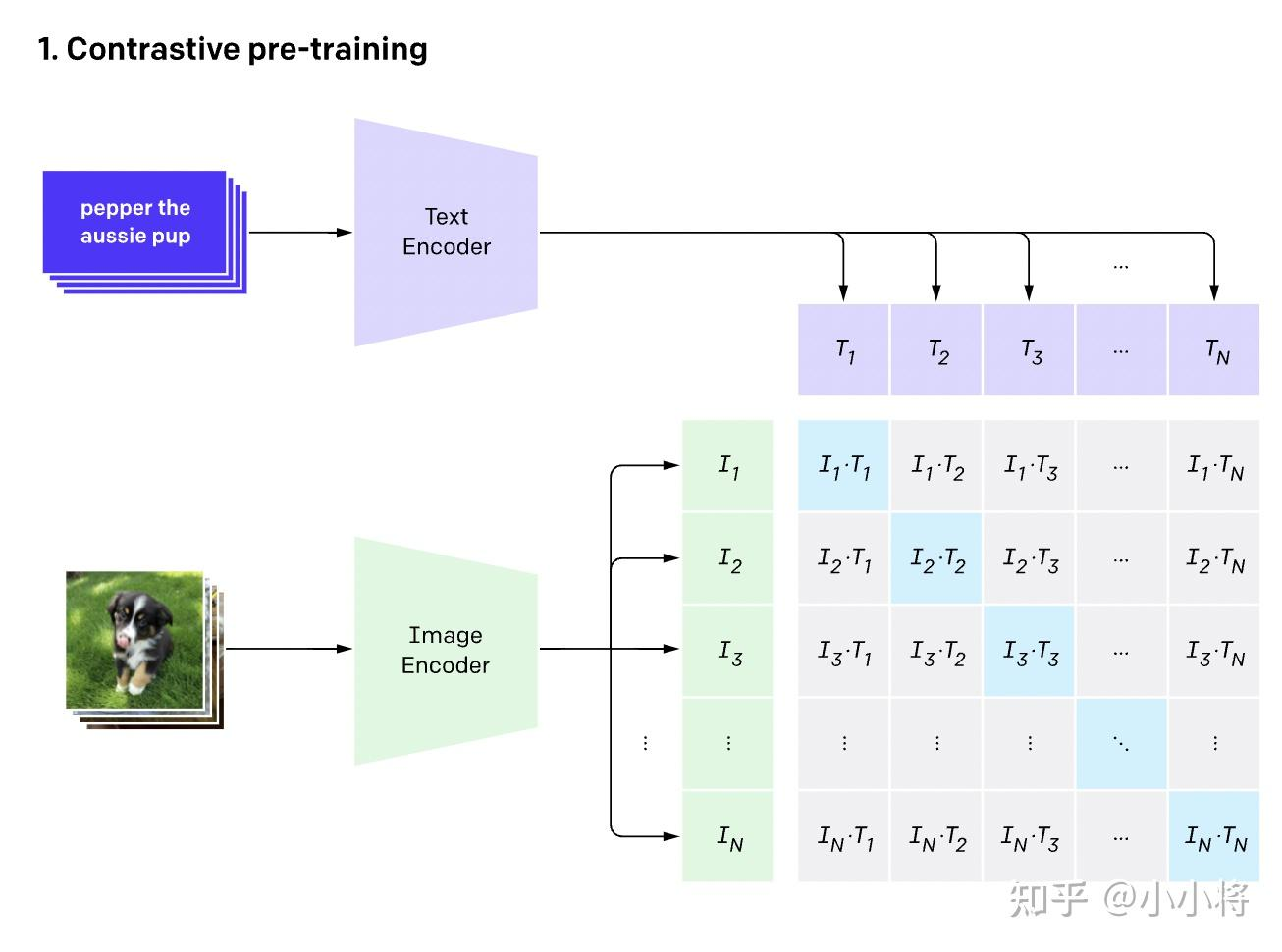
 多模态初探——驾驶汽车虚拟仿真视频数据理解 近期Datawhale组织了《2023全球智能汽车AI挑战赛——赛道二:智能驾驶汽车虚拟仿真视频数据理解赛道》比赛的赛事实践活动赛题:智能驾驶汽车虚拟仿真视频数据理解赛道任务:输入:元宇宙仿真平台生成的前视摄像头虚拟视频数据(8-10秒左右);输出:对视频中的信息进行综合理解,以指定的json文件格式,按照数据说明中的关键词(key)填充描述型的文本信息(value,中文/英文均可以);baseline理解CLIPbaseline主要采用了CLIP模型:CLIP是用文本作为监督信号来训练可迁移的视觉模型,特此学习一下CLIPCLIP参考资料:https://zhuanlan.zhihu.com/p/493489688How CLIP WorksCLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,CLIP的训练数据是文本-图像对:(Text, Img)一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。如下图所示,CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。Text Encoder:text transformerImage Encoder: CNN or vision transformer这里对提取的文本特征和图像特征进行对比学习。对于一个包含N个文本-图像对的训练batch,将N个文本特征和N个图像特征两两组合,CLIP模型会预测出N²个可能的文本-图像对的相似度,这里的相似度直接计算文本特征和图像特征的余弦相似性(cosine similarity),即上图所示的矩阵。这里共有N个正样本,即真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的N²−N个文本-图像对为负样本,那么CLIP的训练目标就是最大N个正样本的相似度,同时最小化N²−N个负样本的相似度How to zero-shot by CLIP与YOLO中使用的先预训练然后微调不同,CLIP可以直接实现zero-shot的图像分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类根据任务的分类标签构建每个类别的描述文本:A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为N,那么将得到N个文本特征;将要预测的图像送入Image Encoder得到图像特征,然后与N个文本特征计算缩放的余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果,进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率在飞桨平台使用CLIP# 由于在平台没有默认安装CLIP模块,故需要先执行安装命令 !pip install paddleclip# 安装完后直接通过clip导入 from clip import tokenize, load_model # 载入预训练模型 model, transforms = load_model('ViT_B_32', pretrained=True)Pillow和OpenCV由于在之前仅仅接触过几次cv2和pil,都是直接从网上搜完代码直接调用的,没有深入里结果里面的具体含义,这次借着本次组队学习的机会,系统梳理一下cv2和pil的API先来看下本次baseline所用到的APIPIL# 导入pillow库中的Image from PIL import Image # 读入文件后是PIL类型(RGB) img = Image.open("zwk.png") # 补充:pytorch的顺序是(batch,c,h,w),tensorflow、numpy中是(batch,h,w,c)cv2# 导入cv2 import cv2 # 连接摄像头或读取视频文件,传入数字n代表第n号摄像头(从0开始),传入路径读取视频文件 cap = cv2.VideoCapture() # 按帧读取视频,ret为bool,frame为帧 ret, frame = cap.read() # 获取总帧数 cap.get(cv2.CAP_PROP_FRAME_COUNT) # 如果要抄中间的帧,需要先跳转到指定位置 cap.set(cv2.CAP_PROP_POS_FRAMES, n) # 由于cv2读取的图片默认BGR,而模型需要传入标准的RGB形式图片 image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 色彩通道转换:BGR -> RGB改进将需要预测的keywords改为["weather", "road_structure", "period", 'scerario'],可以使分数从93提升到119,看来CLIP对于识别一些诸如天气环境等静态信息还是比较有优势的。修改抽帧位置,但没有改进,可以再次尝试抽取多帧进行投票。(其实还试过切换为GPU,把整个视频所有帧都抽出来组成一个batch放进去计算整体概率,但是效果也不好)frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 获取视频总帧数 middle_frame_index = frame_count // 2 cap.set(cv2.CAP_PROP_POS_FRAMES, middle_frame_index) # 设置跳转当前位置到中间帧
多模态初探——驾驶汽车虚拟仿真视频数据理解 近期Datawhale组织了《2023全球智能汽车AI挑战赛——赛道二:智能驾驶汽车虚拟仿真视频数据理解赛道》比赛的赛事实践活动赛题:智能驾驶汽车虚拟仿真视频数据理解赛道任务:输入:元宇宙仿真平台生成的前视摄像头虚拟视频数据(8-10秒左右);输出:对视频中的信息进行综合理解,以指定的json文件格式,按照数据说明中的关键词(key)填充描述型的文本信息(value,中文/英文均可以);baseline理解CLIPbaseline主要采用了CLIP模型:CLIP是用文本作为监督信号来训练可迁移的视觉模型,特此学习一下CLIPCLIP参考资料:https://zhuanlan.zhihu.com/p/493489688How CLIP WorksCLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,CLIP的训练数据是文本-图像对:(Text, Img)一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。如下图所示,CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。Text Encoder:text transformerImage Encoder: CNN or vision transformer这里对提取的文本特征和图像特征进行对比学习。对于一个包含N个文本-图像对的训练batch,将N个文本特征和N个图像特征两两组合,CLIP模型会预测出N²个可能的文本-图像对的相似度,这里的相似度直接计算文本特征和图像特征的余弦相似性(cosine similarity),即上图所示的矩阵。这里共有N个正样本,即真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的N²−N个文本-图像对为负样本,那么CLIP的训练目标就是最大N个正样本的相似度,同时最小化N²−N个负样本的相似度How to zero-shot by CLIP与YOLO中使用的先预训练然后微调不同,CLIP可以直接实现zero-shot的图像分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类根据任务的分类标签构建每个类别的描述文本:A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为N,那么将得到N个文本特征;将要预测的图像送入Image Encoder得到图像特征,然后与N个文本特征计算缩放的余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果,进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率在飞桨平台使用CLIP# 由于在平台没有默认安装CLIP模块,故需要先执行安装命令 !pip install paddleclip# 安装完后直接通过clip导入 from clip import tokenize, load_model # 载入预训练模型 model, transforms = load_model('ViT_B_32', pretrained=True)Pillow和OpenCV由于在之前仅仅接触过几次cv2和pil,都是直接从网上搜完代码直接调用的,没有深入里结果里面的具体含义,这次借着本次组队学习的机会,系统梳理一下cv2和pil的API先来看下本次baseline所用到的APIPIL# 导入pillow库中的Image from PIL import Image # 读入文件后是PIL类型(RGB) img = Image.open("zwk.png") # 补充:pytorch的顺序是(batch,c,h,w),tensorflow、numpy中是(batch,h,w,c)cv2# 导入cv2 import cv2 # 连接摄像头或读取视频文件,传入数字n代表第n号摄像头(从0开始),传入路径读取视频文件 cap = cv2.VideoCapture() # 按帧读取视频,ret为bool,frame为帧 ret, frame = cap.read() # 获取总帧数 cap.get(cv2.CAP_PROP_FRAME_COUNT) # 如果要抄中间的帧,需要先跳转到指定位置 cap.set(cv2.CAP_PROP_POS_FRAMES, n) # 由于cv2读取的图片默认BGR,而模型需要传入标准的RGB形式图片 image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 色彩通道转换:BGR -> RGB改进将需要预测的keywords改为["weather", "road_structure", "period", 'scerario'],可以使分数从93提升到119,看来CLIP对于识别一些诸如天气环境等静态信息还是比较有优势的。修改抽帧位置,但没有改进,可以再次尝试抽取多帧进行投票。(其实还试过切换为GPU,把整个视频所有帧都抽出来组成一个batch放进去计算整体概率,但是效果也不好)frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 获取视频总帧数 middle_frame_index = frame_count // 2 cap.set(cv2.CAP_PROP_POS_FRAMES, middle_frame_index) # 设置跳转当前位置到中间帧 -
Jupyter Notebook添加删除查看kernel 查看 Jupyter notebook kerneljupyter kernelspec list添加kernel# 首先进入道相应环境中 python -m pip install ipykernel python -m ipykernel install --user --name=kernelname --display-name showname # name为创建的文件夹名,showname为jupyter notebook展示的内核名删除jupyter kerneljupyter kernelspec remove kernelname
-
【Datawhale夏令营第三期】用户新增预测挑战赛 前言又又又参加了Datawhale的AI夏令营第二期的机器学习赛道~,没错这次还是机器学习(外加运营助教)baseline:https://aistudio.baidu.com/aistudio/projectdetail/6618108赛事任务基于提供的样本构建模型,预测用户的新增情况数据说明udmap: 以dict形式给出,需要自定义函数解析common_ts: 事件发生时间,可使用df.dt进行解析x1-x8: 某种特征,但不清楚含义,可通过后续画图分析进行处理target: 预测目标0或1二分类评估指标还是f1,F1 score解释: https://www.9998k.cn/archives/169.htmlF1 scoreF1 score = 2 * (precision * recall) / (precision + recall)precision and recall第一次看的时候还不太懂precision和recall的含义,也总结一下首先定义以下几个概念:TP(True Positive):真阳性TN (True Negative) : 真阴性FP(False Positive):假阳性FN(False Negative):假阴性precision = TP / (TP + FP)recall = TP / (TP + FN)accuracy = (TP + TN) / (TP + TN + FP + FN)分析baseline分析跑出来是0.62+使用了决策树模型进行训练对udmap特征进行了提取计算了eid的freq和mean通过df.dt提取了hour信息特征提取除去baseline的特征外,又借鉴了锂电池那次的baseline,提取了如下特征:dayofweekweekofyeardayofyearis_weekend调整后的分数为:0.75train_data['common_ts_hour'] = train_data['common_ts'].dt.hour test_data['common_ts_hour'] = test_data['common_ts'].dt.hour train_data['common_ts_minute'] = train_data['common_ts'].dt.minute + train_data['common_ts_hour'] * 60 test_data['common_ts_minute'] = test_data['common_ts'].dt.minute + test_data['common_ts_hour'] * 60 train_data['dayofweek'] = train_data['common_ts'].dt.dayofweek test_data['dayofweek'] = test_data['common_ts'].dt.dayofweek train_data["weekofyear"] = train_data["common_ts"].dt.isocalendar().week.astype(int) test_data["weekofyear"] = test_data["common_ts"].dt.isocalendar().week.astype(int) train_data["dayofyear"] = train_data["common_ts"].dt.dayofyear test_data["dayofyear"] = test_data["common_ts"].dt.dayofyear train_data["day"] = train_data["common_ts"].dt.day test_data["day"] = test_data["common_ts"].dt.day train_data['is_weekend'] = train_data['dayofweek'] // 6 test_data['is_weekend'] = test_data['dayofweek'] // 6x1-x8特征提取train_data['x1_freq'] = train_data['x1'].map(train_data['x1'].value_counts()) test_data['x1_freq'] = test_data['x1'].map(train_data['x1'].value_counts()) test_data['x1_freq'].fillna(test_data['x1_freq'].mode()[0], inplace=True) train_data['x1_mean'] = train_data['x1'].map(train_data.groupby('x1')['target'].mean()) test_data['x1_mean'] = test_data['x1'].map(train_data.groupby('x1')['target'].mean()) test_data['x1_mean'].fillna(test_data['x1_mean'].mode()[0], inplace=True) train_data['x2_freq'] = train_data['x2'].map(train_data['x2'].value_counts()) test_data['x2_freq'] = test_data['x2'].map(train_data['x2'].value_counts()) test_data['x2_freq'].fillna(test_data['x2_freq'].mode()[0], inplace=True) train_data['x2_mean'] = train_data['x2'].map(train_data.groupby('x2')['target'].mean()) test_data['x2_mean'] = test_data['x2'].map(train_data.groupby('x2')['target'].mean()) test_data['x2_mean'].fillna(test_data['x2_mean'].mode()[0], inplace=True) train_data['x3_freq'] = train_data['x3'].map(train_data['x3'].value_counts()) test_data['x3_freq'] = test_data['x3'].map(train_data['x3'].value_counts()) test_data['x3_freq'].fillna(test_data['x3_freq'].mode()[0], inplace=True) train_data['x4_freq'] = train_data['x4'].map(train_data['x4'].value_counts()) test_data['x4_freq'] = test_data['x4'].map(train_data['x4'].value_counts()) test_data['x4_freq'].fillna(test_data['x4_freq'].mode()[0], inplace=True) train_data['x6_freq'] = train_data['x6'].map(train_data['x6'].value_counts()) test_data['x6_freq'] = test_data['x6'].map(train_data['x6'].value_counts()) test_data['x6_freq'].fillna(test_data['x6_freq'].mode()[0], inplace=True) train_data['x6_mean'] = train_data['x6'].map(train_data.groupby('x6')['target'].mean()) test_data['x6_mean'] = test_data['x6'].map(train_data.groupby('x6')['target'].mean()) test_data['x6_mean'].fillna(test_data['x6_mean'].mode()[0], inplace=True) train_data['x7_freq'] = train_data['x7'].map(train_data['x7'].value_counts()) test_data['x7_freq'] = test_data['x7'].map(train_data['x7'].value_counts()) test_data['x7_freq'].fillna(test_data['x7_freq'].mode()[0], inplace=True) train_data['x7_mean'] = train_data['x7'].map(train_data.groupby('x7')['target'].mean()) test_data['x7_mean'] = test_data['x7'].map(train_data.groupby('x7')['target'].mean()) test_data['x7_mean'].fillna(test_data['x7_mean'].mode()[0], inplace=True) train_data['x8_freq'] = train_data['x8'].map(train_data['x8'].value_counts()) test_data['x8_freq'] = test_data['x8'].map(train_data['x8'].value_counts()) test_data['x8_freq'].fillna(test_data['x8_freq'].mode()[0], inplace=True) train_data['x8_mean'] = train_data['x8'].map(train_data.groupby('x8')['target'].mean()) test_data['x8_mean'] = test_data['x8'].map(train_data.groupby('x8')['target'].mean()) test_data['x8_mean'].fillna(test_data['x8_mean'].mode()[0], inplace=True)实测使用众数填充会比0填充好一点实测分数 0.76398无脑大招:AutoGluon直接上代码:import pandas as pd import numpy as np train_data = pd.read_csv('用户新增预测挑战赛公开数据/train.csv') test_data = pd.read_csv('用户新增预测挑战赛公开数据/test.csv') #autogluon from autogluon.tabular import TabularDataset, TabularPredictor clf = TabularPredictor(label='target') clf.fit( TabularDataset(train_data.drop(['uuid'], axis=1)), ) print("预测的正确率为:",clf.evaluate( TabularDataset(train_data.drop(['uuid'], axis=1)), ) ) pd.DataFrame({ 'uuid': test_data['uuid'], 'target': clf.predict(test_data.drop(['uuid'], axis=1)) }).to_csv('submit.csv', index=None)AutoGluon分数:0.79868使用x1-x8识别用户特征参考自Ivan大佬import pandas as pd import numpy as np train_data = pd.read_csv('用户新增预测挑战赛公开数据/train.csv') test_data = pd.read_csv('用户新增预测挑战赛公开数据/test.csv') user_df = train_data.groupby(by=['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8'])['target'].mean().reset_index( name='user_prob') from sklearn.tree import DecisionTreeClassifier for i in range(user_df.shape[0]): x1 = user_df.iloc[i, 0] x2 = user_df.iloc[i, 1] x3 = user_df.iloc[i, 2] x4 = user_df.iloc[i, 3] x5 = user_df.iloc[i, 4] x6 = user_df.iloc[i, 5] x7 = user_df.iloc[i, 6] x8 = user_df.iloc[i, 7] sub_train = train_data.loc[ (train_data['x1'] == x1) & (train_data['x2'] == x2) & (train_data['x3'] == x3) & (train_data['x4'] == x4) & (train_data['x5'] == x5) & (train_data['x6'] == x6) & (train_data['x7'] == x7) & (train_data['x8'] == x8) ] sub_test = test_data.loc[ (test_data['x1'] == x1) & (test_data['x2'] == x2) & (test_data['x3'] == x3) & (test_data['x4'] == x4) & (test_data['x5'] == x5) & (test_data['x6'] == x6) & (test_data['x7'] == x7) & (test_data['x8'] == x8) ] # print(sub_train.columns) clf = DecisionTreeClassifier() clf.fit( sub_train.loc[:, ['eid', 'common_ts']], sub_train['target'] ) try: test_data.loc[ (test_data['x1'] == x1) & (test_data['x2'] == x2) & (test_data['x3'] == x3) & (test_data['x4'] == x4) & (test_data['x5'] == x5) & (test_data['x6'] == x6) & (test_data['x7'] == x7) & (test_data['x8'] == x8), ['target'] ] = clf.predict( test_data.loc[ (test_data['x1'] == x1) & (test_data['x2'] == x2) & (test_data['x3'] == x3) & (test_data['x4'] == x4) & (test_data['x5'] == x5) & (test_data['x6'] == x6) & (test_data['x7'] == x7) & (test_data['x8'] == x8), ['eid', 'common_ts']] ) except: pass test_data.fillna(0, inplace=True) test_data['target'] = test_data.target.astype(int) test_data[['uuid','target']].to_csv('submit_2.csv', index=None)实测分数:0.831最后 修改代码,把fillna替换为如下代码from sklearn.tree import DecisionTreeClassifier clf = DecisionTreeClassifier() clf.fit( train_data.drop(['udmap', 'common_ts', 'uuid', 'target', 'common_ts_hour'], axis=1), train_data['target'] ) test_data.loc[pd.isna(test_data['target']),'target'] = \ clf.predict( test_data.loc[ pd.isna(test_data['target']), test_data.drop(['udmap', 'common_ts', 'uuid', 'target', 'common_ts_hour'], axis=1).columns] )最终分数: 0.8321
-
【Datawhale夏令营第二期】CatBoost如何使用GPU 前言参加了Datawhale的AI夏令营第二期的机器学习赛道~,没错这次还是机器学习 baseline:https://aistudio.baidu.com/aistudio/projectdetail/6598302?sUid=2554132&shared=1&ts=1690895519028问题由于在使用cpu训练时很慢,且飞浆又为我们免费提供了GPU算力,就像尝试如何使用GPU训练进行加速解决catboost官方文档: https://catboost.ai/docs/ 在文档中不难找到调用GPU的方式: https://catboost.ai/docs/features/training-on-gpu# For example, use the following code to train a classification model on GPU: from catboost import CatBoostClassifier train_data = [[0, 3], [4, 1], [8, 1], [9, 1]] train_labels = [0, 0, 1, 1] model = CatBoostClassifier(iterations=1000, task_type="GPU", devices='0:1') model.fit(train_data, train_labels, verbose=False) catboost相比于第一期的baseline所使用的LightGBM,无需再使用root环境安装额外的gpu环境即可调用gpu在本次的baseline中,只需在cv_model函数中的line15中的params: dict中添加一个键即可:'task_type' : 'GPU'芜湖~速度起飞~~~
-
【Datawhale】机器学习赛道——锂离子电池生产参数调控及生产温度预测挑战赛 前言Datawhale组织了一次人工智能相关的线上夏令营活动一共分为三个赛道:机器学习、自然语言处理、计算机视觉由于我还是个菜菜,就选择了机器学习赛道来练习一下基础赛事任务初赛提供了电炉17个温区的实际生产数据,分别是电炉上部17组加热棒设定温度T1-1~T1-17,电炉下部17组加热棒设定温度T2-1~T2-17,底部17组进气口的设定进气流量V1-V17,选手需要根据提供的数据样本构建模型,预测电炉上下部空间17个测温点的测量温度值。数据说明1)进气流量2)加热棒上部温度设定值3)加热棒下部温度设定值4)上部空间测量温度5)下部空间测量温度每项数据各17个分析赛题给出的是根据前三项数据预测后两项数据,但在给出的数据集中(可能)还有一项数据为时间信息(日期+时间),不确定是否会对结果产生实质性的作用Baseline分析baseline主要运用了sklearn和lightgbm机器学习模型进行数据处理和训练,相比于是之前使用的pytorch,更加适合机器学习数据挖掘的任务,也就是本赛题,pytorch多用于深度学习网络的构建和训练。point使用submit["序号"] = test_dataset["序号"]对最后提交的数据及进行序号对齐使用sklearn中的train_test_split模块进行训练集和验证集的分割定义了time_feature函数用于时间数据的处理,而我之前没有考虑到时间因素便直接给Drop掉了上分技巧首先要选用合适的模型,其次要合理调整超参。我在调整超参时主要是通过观察训练集和验证集的loss来查看模型的拟合程度,进而对超参进行调整。代码在没看到Baseline之前,也尝试过使用多层网络来做,但是出现了过拟合现象,最好成绩才跑到了7.9分(预估MAE为4.9)贴一下之前的代码:#!/usr/bin/env python # coding: utf-8 # In[25]: import pandas as pd import torch import os # In[26]: pd.read_csv('train.csv') # In[27]: config = { 'lr': 6e-3, 'batch_size': 256, 'epoch': 180, 'device': 'cuda' if torch.cuda.is_available() else 'cpu', 'res': ['上部温度'+str(i+1) for i in range(17)] + ['下部温度'+str(i+1) for i in range(17)], 'ignore':['序号', '时间'], 'cate_cols': [], 'num_cols': ['上部温度设定'+str(i+1) for i in range(17)] + ['下部温度设定'+str(i+1) for i in range(17)] + ['流量'+str(i+1) for i in range(17)], 'dataset_path': './', 'weight_decay': 0.01 } # In[28]: raw_data = pd.read_csv(os.path.join(config['dataset_path'], 'train.csv')) test_data = pd.read_csv(os.path.join(config['dataset_path'], 'test.csv')) raw_data = pd.concat([raw_data, test_data]) raw_data # In[28]: # In[29]: for i in raw_data.columns: print(i,"--->\t",len(raw_data[i].unique())) # In[30]: def oneHotEncode(df, colNames): for col in colNames: dummies = pd.get_dummies(df[col], prefix=col) df = pd.concat([df, dummies],axis=1) df.drop([col], axis=1, inplace=True) return df # In[31]: raw_data # In[32]: # 处理离散数据 for col in config['cate_cols']: raw_data[col] = raw_data[col].fillna('-1') raw_data = oneHotEncode(raw_data, config['cate_cols']) # 处理连续数据 for col in config['num_cols']: raw_data[col] = raw_data[col].fillna(0) # raw_data[col] = (raw_data[col]-raw_data[col].min()) / (raw_data[col].max()-raw_data[col].min()) # In[33]: for i in raw_data.columns: print(i,"--->\t",len(raw_data[i].unique())) # In[34]: raw_data # In[35]: raw_data.drop(config['ignore'], axis=1, inplace=True) # In[36]: all_data = raw_data.astype('float32') # In[37]: all_data # In[ ]: # 暂存处理后的test数据集 test_data = all_data[pd.isna(all_data['下部温度1'])] test_data.to_csv('./one_hot_test.csv') # In[ ]: # In[ ]: train_data = all_data[pd.notna(all_data['下部温度1'])] # In[ ]: # 打乱 train_data = train_data.sample(frac=1) train_data.shape # In[ ]: # 分离目标 train_target = train_data[config['res']] train_data.drop(config['res'], axis=1, inplace=True) train_data.shape # In[ ]: train_target.to_csv('./train_target.csv') # In[ ]: # 分离出验证集,用于观察拟合情况 validation_data = train_data[:800] train_data = train_data[800:] validation_target = train_target[:800] train_target = train_target[800:] validation_data.shape, train_data.shape, validation_target.shape, train_target.shape # In[ ]: from torch import nn # 定义Residual Block class ResidualBlock(nn.Module): def __init__(self, in_features, out_features, dropout_rate=0.5): super(ResidualBlock, self).__init__() self.linear1 = nn.Linear(in_features, out_features) self.dropout = nn.Dropout(dropout_rate) self.linear2 = nn.Linear(out_features, out_features) def forward(self, x): identity = x out = nn.relu(self.linear1(x)) out = self.dropout(out) out = self.linear2(out) out += identity out = nn.relu(out) return out # In[ ]: from torch import nn # 定义网络结构 class Network(nn.Module): def __init__(self, in_dim, hidden_1, hidden_2, hidden_3, weight_decay=0.01): super().__init__() self.layers = nn.Sequential( nn.Linear(in_dim, hidden_1), # # nn.Dropout(0.49), nn.LeakyReLU(), nn.BatchNorm1d(hidden_1), # nn.Linear(hidden_1, hidden_2), # nn.Dropout(0.2), # nn.LeakyReLU(), # nn.BatchNorm1d(hidden_2), # nn.Linear(hidden_2, hidden_3), # nn.Dropout(0.2), # nn.LeakyReLU(), # nn.BatchNorm1d(hidden_3), nn.Linear(hidden_1, 34) ) # 将权重衰减系数作为类的属性 self.weight_decay = weight_decay def forward(self, x): y = self.layers(x) return y # In[ ]: train_data.shape[1] # In[ ]: # 定义网络 model = Network(train_data.shape[1], 256, 128, 64) model.to(config['device']) try: model.load_state_dict(torch.load('model.pth', map_location=config['device'])) except Exception: # 使用Xavier初始化权重 for line in model.layers: if type(line) == nn.Linear: print(line) nn.init.kaiming_uniform_(line.weight) # In[ ]: train_data.columns # In[ ]: import torch # 将数据转化为tensor,并移动到cpu或cuda上 train_features = torch.tensor(train_data.values, dtype=torch.float32, device=config['device']) train_num = train_features.shape[0] train_labels = torch.tensor(train_target.values, dtype=torch.float32, device=config['device']) validation_features = torch.tensor(validation_data.values, dtype=torch.float32, device=config['device']) validation_num = validation_features.shape[0] validation_labels = torch.tensor(validation_target.values, dtype=torch.float32, device=config['device']) # del train_data, train_target, validation_data, validation_target, raw_data, all_data, test_data # 特征长度 train_features[1].shape # In[ ]: # train_features # In[ ]: # config['lr'] = 3e-3 # In[ ]: from torch import optim # 在定义优化器时,传入网络中的weight_decay参数 def create_optimizer(model, learning_rate, weight_decay): return optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay) # 定义损失函数和优化器 # criterion = nn.MSELoss() criterion = torch.nn.L1Loss() criterion.to(config['device']) optimizer = optim.Adam(model.parameters(), lr=config['lr']) loss_fn = torch.nn.L1Loss() # In[ ]: def val(model, feature, label): model.eval() pred = model(feature) pred = pred.squeeze() res = loss_fn(pred, label).item() return res # In[ ]: mse_list = [] # In[ ]: # 在训练过程中添加L2正则化项 def train(model, train_features, train_labels, optimizer, criterion, weight_decay): model.train() for i in range(0, train_num, config['batch_size']): end = i + config['batch_size'] if i + config['batch_size'] > train_num - 1: end = train_num - 1 mini_batch = train_features[i: end] mini_batch_label = train_labels[i: end] pred = model(mini_batch) pred = pred.squeeze() loss = criterion(pred, mini_batch_label) # 添加L2正则化项 # l2_reg = torch.tensor(0., device=config['device']) # for param in model.parameters(): # l2_reg += torch.norm(param, p=2) # loss += weight_decay * l2_reg if torch.isnan(loss): break optimizer.zero_grad() loss.backward() optimizer.step() # In[ ]: # config['epoch'] = 4096 for epoch in range(config['epoch']): print(f'Epoch[{epoch + 1}/{config["epoch"]}]') model.eval() train_mse = val(model, train_features[:config['batch_size']], train_labels[:config['batch_size']]) validation_mse = val(model, validation_features, validation_labels) mse_list.append((train_mse, validation_mse)) print(f"epoch:{epoch + 1} Train_MSE: {train_mse} Validation_MSE: {validation_mse}") model.train() train(model, train_features, train_labels, optimizer, criterion, weight_decay=config['weight_decay']) torch.save(model.state_dict(), 'model.pth') # In[ ]: import matplotlib.pyplot as plt import numpy as np y1, y2 = zip(*mse_list) x = np.arange(0, len(y1)) plt.plot(x, y1, label='train') plt.plot(x, y2, label='valid') plt.xlabel("epoch") plt.ylabel("Loss: MSE") plt.legend() plt.show()