

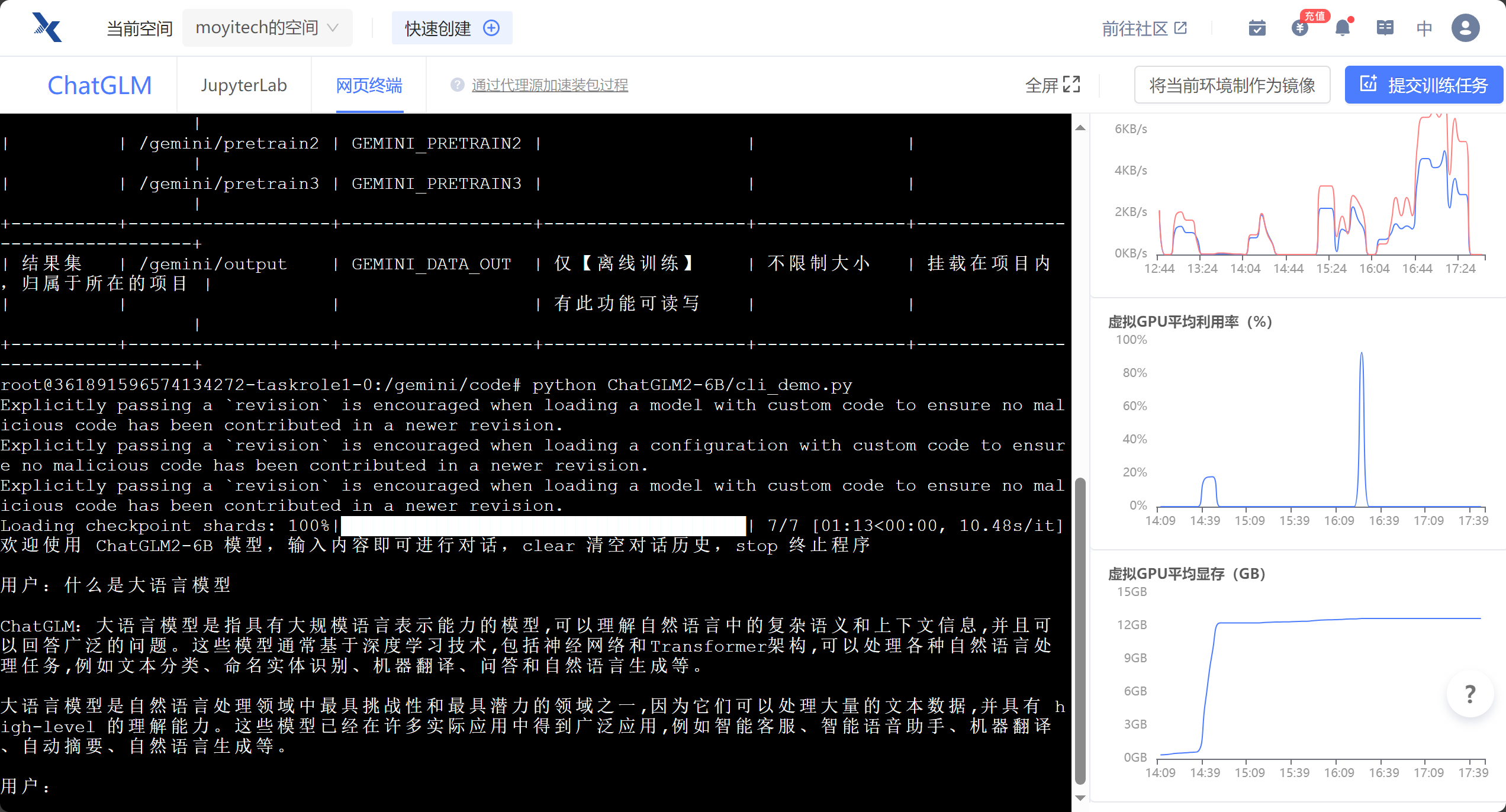
使用趋动云的在线Jupyter Notebook部署模型
环境配置很简单,直接使用预置的镜像即可
环境:
- Python 3
- TensorFlow 2
代码 + 注释:
import argparse
import tensorflow as tf
import os
parser = argparse.ArgumentParser(description='Process some integers') # 使用argparse创建一个可以解析命令行参数的工具,description为描述信息
parser.add_argument('--mode', default='train', help='train or test')
parser.add_argument("--num_epochs", default=5, type=int) # 设置epochs
parser.add_argument("--batch_size", default=32, type=int) # 设置batch_seze
parser.add_argument("--learning_rate", default=0.001) # 设置learning_rate
parser.add_argument("--data_dir", default="/gemini/data-1")
parser.add_argument("--train_dir", default="/gemini/output")
args = parser.parse_args() # 将解析的结果存储在args中
# 图片的前置处理
def _decode_and_resize(filename, label):
image_string = tf.io.read_file(filename) # 从文件中读取
image_decoded = tf.image.decode_jpeg(image_string, channels=3) # 解码jpeg为rgb三通道
image_resized = tf.image.resize(image_decoded, [150, 150]) / 255.0 # 将图片缩放、归一化
return image_resized, label
if __name__ == "__main__":
train_dir = args.data_dir + "/train"
cats = []
dogs = []
for file in os.listdir(train_dir): # 遍历文件夹
if file.startswith("dog"):
dogs.append(train_dir + "/" + file)
else:
cats.append(train_dir + "/" + file)
print("dogSize:%d catSize:%d" % (len(cats), len(dogs)))
train_cat_filenames = tf.constant(cats[:10000]) # 将文件名列表转化为张量
train_dog_filenames = tf.constant(dogs[:10000])
train_filenames = tf.concat([train_cat_filenames, train_dog_filenames], axis=-1) # axis=-1表示最后一个维度
train_labels = tf.concat([
tf.zeros(train_cat_filenames.shape, dtype=tf.int32), # 猫标为0
tf.ones(train_dog_filenames.shape, dtype=tf.int32) # 狗标为1
], axis=-1)
train_dataset = tf.data.Dataset.from_tensor_slices((train_filenames, train_labels)) # 创建一个dataset
train_dataset = train_dataset.map(
map_func=_decode_and_resize,
num_parallel_calls=tf.data.experimental.AUTOTUNE # 指定为并行调用
)
train_dataset = train_dataset.shuffle(buffer_size=20000) # 打乱
train_dataset = train_dataset.batch(args.batch_size) # 设置batch_size
train_dataset = train_dataset.prefetch(tf.data.experimental.AUTOTUNE) # 自动调整并行化程度,使训练时可异步预取数据,减少训练时间
model = tf.keras.Sequential([ # 定义模型网络
tf.keras.layers.Conv2D(32, 3, activation="relu", input_shape=(150, 150, 3)),
tf.keras.layers.MaxPool2D(),
tf.keras.layers.Conv2D(64, 3, activation="relu"),
tf.keras.layers.MaxPool2D(),
tf.keras.layers.Conv2D(128, 3, activation="relu"),
tf.keras.layers.MaxPool2D(),
tf.keras.layers.Conv2D(128, 3, activation="relu"),
tf.keras.layers.MaxPool2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(2, activation="softmax")
])
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=args.learning_rate), # 定义优化器为Adam
loss=tf.keras.losses.sparse_categorical_crossentropy, # 定义损失函数为交叉熵
metrics=[tf.keras.metrics.sparse_categorical_accuracy] # 定义模型评估指标为稀疏分类准确率
)
model.fit(train_dataset, epochs=args.num_epochs) # 开始训练
model.save(args.train_dir) # 保存模型
# 构建测试数据集
test_cat_filenames = tf.constant(cats[10000:])
test_dog_filenames = tf.constant(dogs[10000:])
test_filenames = tf.concat([test_cat_filenames, test_dog_filenames], axis=-1)
test_labels = tf.concat([
tf.zeros(test_cat_filenames.shape, dtype=tf.int32),
tf.ones(test_dog_filenames.shape, dtype=tf.int32)
], axis=-1)
test_dataset = tf.data.Dataset.from_tensor_slices((test_filenames, test_labels))
test_dataset = test_dataset.map(_decode_and_resize)
test_dataset = test_dataset.batch(args.batch_size)
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy() # 稀疏分类指标
for images, label in test_dataset:
y_pred = model.predict(images)
sparse_categorical_accuracy.update_state(y_true=label, y_pred=y_pred) # 更新准确率指标的状态
print("test accuracy:%f" % sparse_categorical_accuracy.result()) # 输出结果
训练命令:
python $GEMINI_RUN/DogsVsCats.py --num_epochs 5 --data_dir $GEMINI_DATA_IN1/DogsVsCats/ --train_dir $GEMINI_DATA_OUT最终结果:

学习心得:由于之前接触的都是pytorch,这次第一次接触了TensorFlow,学习到了很多TensorFlow的api和这次demo简洁优美的代码风格

评论 (0)