
搜索到
1
篇与
的结果
-
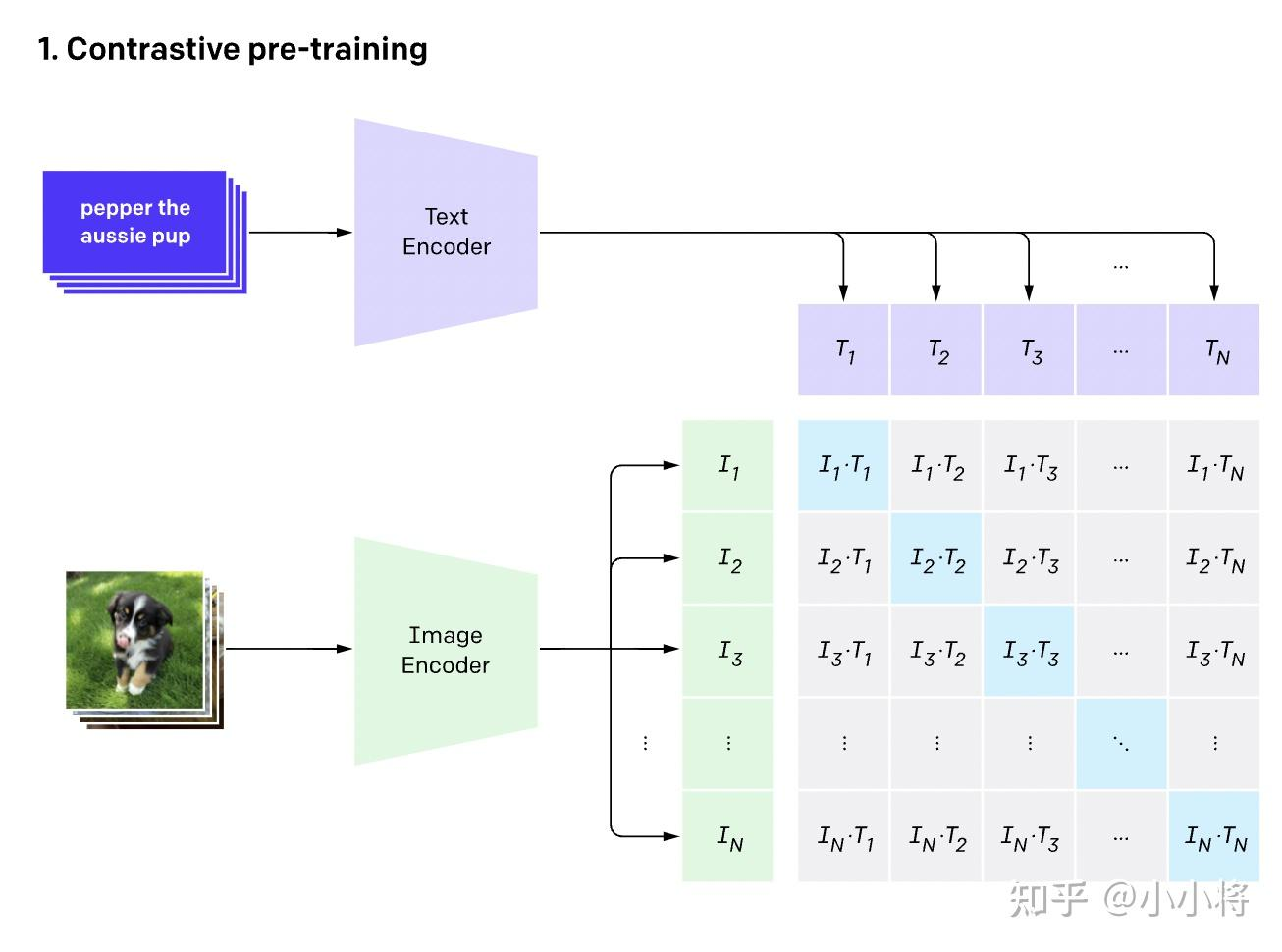
 多模态初探——驾驶汽车虚拟仿真视频数据理解 近期Datawhale组织了《2023全球智能汽车AI挑战赛——赛道二:智能驾驶汽车虚拟仿真视频数据理解赛道》比赛的赛事实践活动赛题:智能驾驶汽车虚拟仿真视频数据理解赛道任务:输入:元宇宙仿真平台生成的前视摄像头虚拟视频数据(8-10秒左右);输出:对视频中的信息进行综合理解,以指定的json文件格式,按照数据说明中的关键词(key)填充描述型的文本信息(value,中文/英文均可以);baseline理解CLIPbaseline主要采用了CLIP模型:CLIP是用文本作为监督信号来训练可迁移的视觉模型,特此学习一下CLIPCLIP参考资料:https://zhuanlan.zhihu.com/p/493489688How CLIP WorksCLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,CLIP的训练数据是文本-图像对:(Text, Img)一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。如下图所示,CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。Text Encoder:text transformerImage Encoder: CNN or vision transformer这里对提取的文本特征和图像特征进行对比学习。对于一个包含N个文本-图像对的训练batch,将N个文本特征和N个图像特征两两组合,CLIP模型会预测出N²个可能的文本-图像对的相似度,这里的相似度直接计算文本特征和图像特征的余弦相似性(cosine similarity),即上图所示的矩阵。这里共有N个正样本,即真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的N²−N个文本-图像对为负样本,那么CLIP的训练目标就是最大N个正样本的相似度,同时最小化N²−N个负样本的相似度How to zero-shot by CLIP与YOLO中使用的先预训练然后微调不同,CLIP可以直接实现zero-shot的图像分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类根据任务的分类标签构建每个类别的描述文本:A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为N,那么将得到N个文本特征;将要预测的图像送入Image Encoder得到图像特征,然后与N个文本特征计算缩放的余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果,进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率在飞桨平台使用CLIP# 由于在平台没有默认安装CLIP模块,故需要先执行安装命令 !pip install paddleclip# 安装完后直接通过clip导入 from clip import tokenize, load_model # 载入预训练模型 model, transforms = load_model('ViT_B_32', pretrained=True)Pillow和OpenCV由于在之前仅仅接触过几次cv2和pil,都是直接从网上搜完代码直接调用的,没有深入里结果里面的具体含义,这次借着本次组队学习的机会,系统梳理一下cv2和pil的API先来看下本次baseline所用到的APIPIL# 导入pillow库中的Image from PIL import Image # 读入文件后是PIL类型(RGB) img = Image.open("zwk.png") # 补充:pytorch的顺序是(batch,c,h,w),tensorflow、numpy中是(batch,h,w,c)cv2# 导入cv2 import cv2 # 连接摄像头或读取视频文件,传入数字n代表第n号摄像头(从0开始),传入路径读取视频文件 cap = cv2.VideoCapture() # 按帧读取视频,ret为bool,frame为帧 ret, frame = cap.read() # 获取总帧数 cap.get(cv2.CAP_PROP_FRAME_COUNT) # 如果要抄中间的帧,需要先跳转到指定位置 cap.set(cv2.CAP_PROP_POS_FRAMES, n) # 由于cv2读取的图片默认BGR,而模型需要传入标准的RGB形式图片 image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 色彩通道转换:BGR -> RGB改进将需要预测的keywords改为["weather", "road_structure", "period", 'scerario'],可以使分数从93提升到119,看来CLIP对于识别一些诸如天气环境等静态信息还是比较有优势的。修改抽帧位置,但没有改进,可以再次尝试抽取多帧进行投票。(其实还试过切换为GPU,把整个视频所有帧都抽出来组成一个batch放进去计算整体概率,但是效果也不好)frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 获取视频总帧数 middle_frame_index = frame_count // 2 cap.set(cv2.CAP_PROP_POS_FRAMES, middle_frame_index) # 设置跳转当前位置到中间帧
多模态初探——驾驶汽车虚拟仿真视频数据理解 近期Datawhale组织了《2023全球智能汽车AI挑战赛——赛道二:智能驾驶汽车虚拟仿真视频数据理解赛道》比赛的赛事实践活动赛题:智能驾驶汽车虚拟仿真视频数据理解赛道任务:输入:元宇宙仿真平台生成的前视摄像头虚拟视频数据(8-10秒左右);输出:对视频中的信息进行综合理解,以指定的json文件格式,按照数据说明中的关键词(key)填充描述型的文本信息(value,中文/英文均可以);baseline理解CLIPbaseline主要采用了CLIP模型:CLIP是用文本作为监督信号来训练可迁移的视觉模型,特此学习一下CLIPCLIP参考资料:https://zhuanlan.zhihu.com/p/493489688How CLIP WorksCLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,CLIP的训练数据是文本-图像对:(Text, Img)一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。如下图所示,CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。Text Encoder:text transformerImage Encoder: CNN or vision transformer这里对提取的文本特征和图像特征进行对比学习。对于一个包含N个文本-图像对的训练batch,将N个文本特征和N个图像特征两两组合,CLIP模型会预测出N²个可能的文本-图像对的相似度,这里的相似度直接计算文本特征和图像特征的余弦相似性(cosine similarity),即上图所示的矩阵。这里共有N个正样本,即真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的N²−N个文本-图像对为负样本,那么CLIP的训练目标就是最大N个正样本的相似度,同时最小化N²−N个负样本的相似度How to zero-shot by CLIP与YOLO中使用的先预训练然后微调不同,CLIP可以直接实现zero-shot的图像分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类根据任务的分类标签构建每个类别的描述文本:A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为N,那么将得到N个文本特征;将要预测的图像送入Image Encoder得到图像特征,然后与N个文本特征计算缩放的余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果,进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率在飞桨平台使用CLIP# 由于在平台没有默认安装CLIP模块,故需要先执行安装命令 !pip install paddleclip# 安装完后直接通过clip导入 from clip import tokenize, load_model # 载入预训练模型 model, transforms = load_model('ViT_B_32', pretrained=True)Pillow和OpenCV由于在之前仅仅接触过几次cv2和pil,都是直接从网上搜完代码直接调用的,没有深入里结果里面的具体含义,这次借着本次组队学习的机会,系统梳理一下cv2和pil的API先来看下本次baseline所用到的APIPIL# 导入pillow库中的Image from PIL import Image # 读入文件后是PIL类型(RGB) img = Image.open("zwk.png") # 补充:pytorch的顺序是(batch,c,h,w),tensorflow、numpy中是(batch,h,w,c)cv2# 导入cv2 import cv2 # 连接摄像头或读取视频文件,传入数字n代表第n号摄像头(从0开始),传入路径读取视频文件 cap = cv2.VideoCapture() # 按帧读取视频,ret为bool,frame为帧 ret, frame = cap.read() # 获取总帧数 cap.get(cv2.CAP_PROP_FRAME_COUNT) # 如果要抄中间的帧,需要先跳转到指定位置 cap.set(cv2.CAP_PROP_POS_FRAMES, n) # 由于cv2读取的图片默认BGR,而模型需要传入标准的RGB形式图片 image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 色彩通道转换:BGR -> RGB改进将需要预测的keywords改为["weather", "road_structure", "period", 'scerario'],可以使分数从93提升到119,看来CLIP对于识别一些诸如天气环境等静态信息还是比较有优势的。修改抽帧位置,但没有改进,可以再次尝试抽取多帧进行投票。(其实还试过切换为GPU,把整个视频所有帧都抽出来组成一个batch放进去计算整体概率,但是效果也不好)frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 获取视频总帧数 middle_frame_index = frame_count // 2 cap.set(cv2.CAP_PROP_POS_FRAMES, middle_frame_index) # 设置跳转当前位置到中间帧